The power of interning: making a time series database 2000x smaller in Rust
This week-end project started by browsing the open-data repository of Paris’ public transport network, which contains various APIs to query real-time departures, current disruptions, etc. The data reuse section caught my eye, as it features external projects that use this open data. In particular, the RATP status website provides a really nice interface to visualize historical disruptions on metro, RER/train and tramway lines.
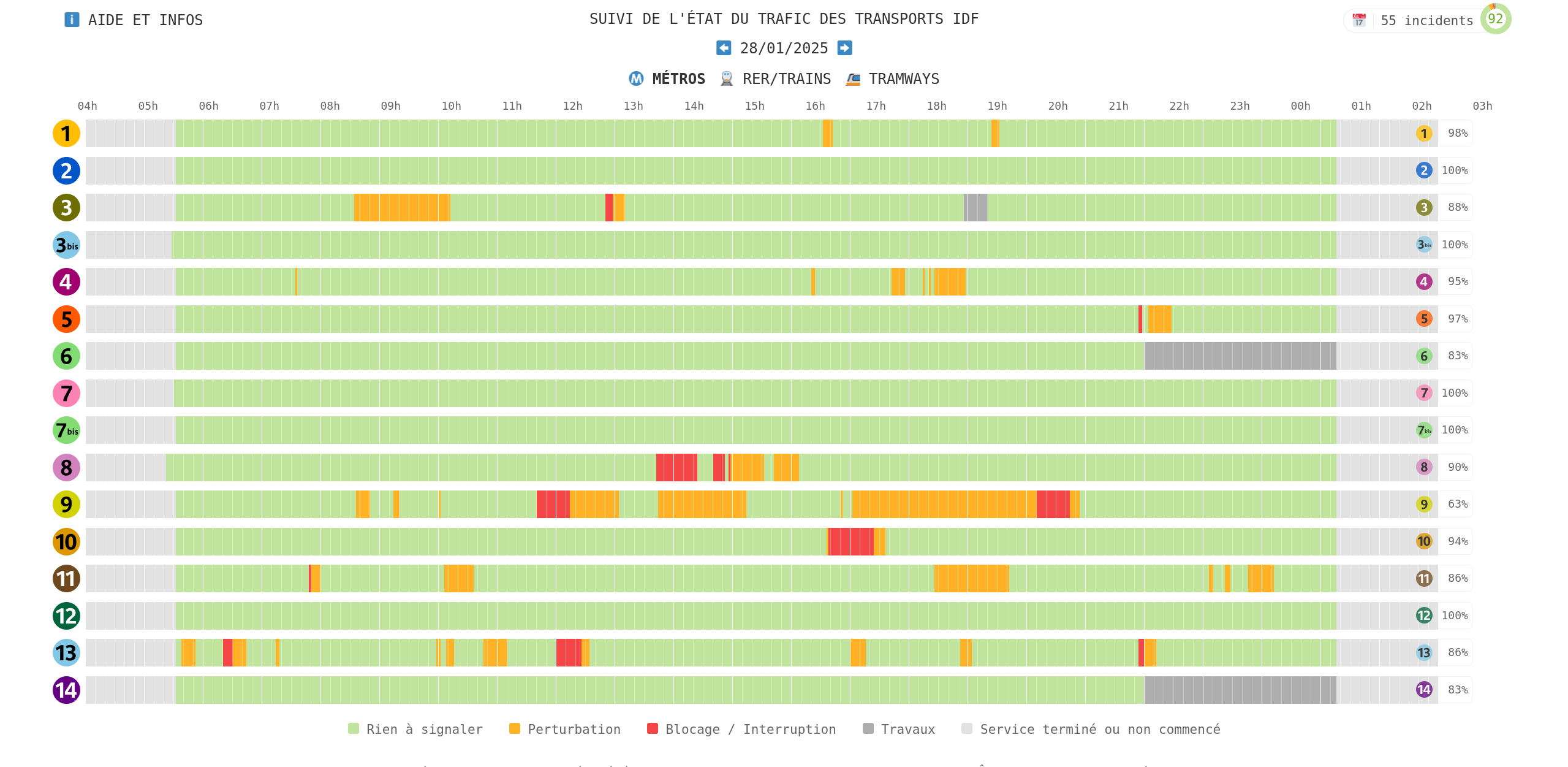 A usual day of disruptions on ratpstatus.fr.
A usual day of disruptions on ratpstatus.fr.
Under the hood, the ratpstatus.fr GitHub repository contains all the JSON files queried from the open-data API, every 2 minutes for almost a year now.
A repository with 188K commits and more than 10 GB of accumulated data at the last commit alone (as measured by git clone --depth=1) is definitely an interesting database choice!
To be clear, this post isn’t in any way a critique of that.
RATP status is an excellent website providing useful information that runs blazingly fast1 and smoothly without the usual bloat you see on the web nowadays.
Nonetheless, the 10 GB of data got me to wonder: can we compress that better, by spending a reasonable amount of time (i.e. a week-end project)? In this deep dive post, I’ll explain how I used the interning design pattern in Rust to compress this data set by a factor of two thousand! We’ll investigate how to best structure the interner itself, how to tune our data schema to work well with it, and likewise how serialization can best leverage interning.
If you’ve got lots of JSON files accumulating in your storage, you should read on!
- Importing the data (135%)
- Interning
- Tuning the schema
- Serialization
- Final result: a lightweight append-only database
- Appendix: optimizing the interning function
Importing the data (135%)
The first step of this experiment was to import the source data. To give a bit more context, each data point was a JSON file with many entries looking like this.
{
"disruptions": [
{
"id": "445a6032-d1ca-11ef-b3f5-0a58a9feac02",
"applicationPeriods": [
{
"begin": "20250113T180000",
"end": "20250228T230000"
}
],
"lastUpdate": "20250113T172013",
"cause": "PERTURBATION",
"severity": "BLOQUANTE",
"title": "Activities in Aincourt",
"message": "<p>Due to work in Aincourt, the Centre and Eglise stops will not be served in both directions of traffic on line 95 15 and in the direction of Magny en Vexin Gare Routière only on line 95 44. <br>From 13/01 until further notice. </p><br>Please refer to Les Cadenas stops"
},
...
}
Let’s import this data into our program!
If you’re not familiar with Rust, this programming language makes it very easy to deserialize data from all sorts of formats via libraries like serde and serde_json.
I’m depending on the following versions in my Cargo.toml manifest.
[dependencies]
serde = { version = "1.0.217", features = ["derive"] }
serde_json = "1.0.137"
With that, we can define a data schema as regular Rust structs/enums and simply annotate them with serde’s Deserialize derive macro to automatically implement deserialization for it.
I recommend using the deny_unknown_fields attribute to make sure unknown JSON fields aren’t silently ignored.
These attributes are documented separately on the serde.rs website (not on docs.rs).
use serde::Deserialize;
#[derive(Debug, Deserialize)]
#[serde(deny_unknown_fields)]
struct Data {
#[serde(rename = "statusCode")]
status_code: Option<i32>,
error: Option<String>,
message: Option<String>,
disruptions: Option<Vec<Disruption>>,
lines: Option<Vec<Line>>,
#[serde(rename = "lastUpdatedDate")]
last_updated_date: Option<String>,
}
One can then trivially deserialize a JSON file into a Data struct with functions like serde_json::from_reader().
// Open a file for reading.
let file = File::open(path)?;
// Add a layer of buffering for performance.
let reader = BufReader::new(file);
// Deserialize the JSON contents into a Data.
let data: Data = serde_json::from_reader(reader)?;
To give more details about the specific data schema I’m importing, each Disruption contains informative fields, as well as a list of time periods during which it applies.
For example, there may be construction work on a line every evening for a month, so there would be an ApplicationPeriod for each of these evenings.
#[derive(Debug, Deserialize)]
#[serde(deny_unknown_fields)]
struct Disruption {
id: String,
#[serde(rename = "applicationPeriods")]
application_periods: Vec<ApplicationPeriod>,
#[serde(rename = "lastUpdate")]
last_update: String,
cause: String,
severity: String,
tags: Option<Vec<String>>,
title: String,
message: String,
disruption_id: Option<String>,
}
#[derive(Debug, Deserialize)]
#[serde(deny_unknown_fields)]
struct ApplicationPeriod {
begin: String,
end: String,
}
The data also contains an index by Lines, listing all the objects (e.g. stations) impacted by disruptions on each metro line.
#[derive(Debug, Deserialize)]
#[serde(deny_unknown_fields)]
struct Line {
id: String,
name: String,
#[serde(rename = "shortName")]
short_name: String,
mode: String,
#[serde(rename = "networkId")]
network_id: String,
#[serde(rename = "impactedObjects")]
impacted_objects: Vec<ImpactedObject>,
}
#[derive(Debug, Deserialize)]
#[serde(deny_unknown_fields)]
struct ImpactedObject {
#[serde(rename = "type")]
typ: String,
id: String,
name: String,
#[serde(rename = "disruptionIds")]
disruption_ids: Vec<String>,
}
Lastly, I wanted to estimate how much space these objects take in memory, in order to benchmark the improvements obtained by interning methods.
Rust’s std::mem::size_of() function returns the “stack” size of an object, but that’s not sufficient as it ignores any data indirectly allocated on the heap (such as via a Vec collection).
Therefore, I defined a new trait and implemented it for the needed types.
trait EstimateSize: Sized {
/// Returns the number of bytes indirectly allocated on the heap by this object.
fn allocated_bytes(&self) -> usize;
/// Returns the total number of bytes that this object uses.
fn estimated_bytes(&self) -> usize {
std::mem::size_of::<Self>() + self.allocated_bytes()
}
}
impl EstimateSize for i32 {
fn allocated_bytes(&self) -> usize {
0 // Nothing allocated on the heap.
}
}
impl EstimateSize for String {
fn allocated_bytes(&self) -> usize {
self.len() // Each item is one byte long. Ignores the string capacity.
}
}
impl<T: EstimateSize> EstimateSize for Vec<T> {
fn allocated_bytes(&self) -> usize {
// Recursively sum each item's total size.
self.iter().map(|x| x.estimated_bytes()).sum()
}
}
For compound types (structs), the implementation visits all the fields.
In principle, this could automatically be implemented by a derive macro (like serde’s Deserialize), but creating a new macro seemed overkill given the scale of my experiment.
impl EstimateSize for Data {
fn allocated_bytes(&self) -> usize {
self.status_code.allocated_bytes()
+ self.error.allocated_bytes()
+ self.message.allocated_bytes()
+ self.disruptions.allocated_bytes()
+ self.lines.allocated_bytes()
+ self.last_updated_date.allocated_bytes()
}
}
With that, reading all the files from May 2024 gave the following result: expanding the 1.1 GB of JSON files into in-memory structs increased the size by 35% (commit d961e6e). Not in the right direction… let’s start optimizing!
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Interning
In this section, I’ll present the basics of the interning pattern, and how to apply it to various types.
Strings (47%)
The first use case that comes to mind in terms of interning is strings, as evidenced by the top Rust interning libraries. We’re not going to use any of these packages, as my goal was to learn more about the inner details of interning.
I stumbled upon a blog post by matklad from 2020 titled Fast and Simple Rust Interner, and my first iteration is inspired by this design.
The main difference is that I wrapped strings into an Rc (reference-counted wrapper) to avoid duplicating them in memory.
If the interner is intended to be used from multiple threads, I’d use an Arc instead, but I’m keeping things simple for this experiment.
So what is an interner? It’s essentially a table of strings, consisting of a vector of strings paired with a hash map that allows looking up if a string is already in the database, and if so at which index in the vector.
use std::collections::HashMap;
use std::rc::Rc;
#[derive(Default)]
struct StringInternerImpl {
vec: Vec<Rc<String>>,
map: HashMap<Rc<String>, usize>,
}
impl StringInternerImpl {
fn intern(&mut self, value: String) -> usize {
if let Some(&id) = self.map.get(&value) {
return id;
}
let id = self.vec.len();
let rc: Rc<String> = Rc::new(value);
self.vec.push(Rc::clone(&rc));
self.map.insert(rc, id);
id
}
fn lookup(&self, id: usize) -> Rc<String> {
Rc::clone(&self.vec[id])
}
}
An interned string is then an index in the interner table. The main advantage of this setup is to reduce the amount of memory used by the program, because an integer index is usually smaller than the full string. This is especially effective when there are many repeated strings.
 Memory layout of strings without and with interning.
Memory layout of strings without and with interning.
There are several possible designs to represent an interned string object: as a first iteration I’ve chosen to pair the index with a reference to the interner that contains it.
struct IString<'a> {
interner: &'a StringInterner,
id: usize,
}
impl<'a> IString<'a> {
fn from(interner: &'a StringInterner, value: String) -> Self {
let id = interner.intern(value);
Self { interner, id }
}
fn lookup(&self) -> Rc<String> {
self.interner.lookup(self.id)
}
}
At this point, you might have noticed that I’ve declared StringInterner and StringInternerImpl types.
What’s the difference?
The answer is that once an IString captures an interner handle &StringInterner, the underlying StringInterner cannot be mutated anymore via an intern() function taking a &mut self parameter, as it would break Rust’s aliasing rules: there cannot be both a &StringInterner and a &mut StringInterner pointing to the same thing at the same time.
This is quite unfortunate, as it prevents interning more than one string!
The way to resolve this conflict is to use interior mutability via the RefCell type.
By defining a StringInterner as a RefCell<StringInternerImpl>, we can intern more values without needing a &mut self reference to the interner.
#[derive(Default)]
struct StringInterner {
inner: RefCell<StringInternerImpl>,
}
impl StringInterner {
// This function takes an immutable reference!
fn intern(&self, value: String) -> usize {
// The borrow_mut() method performs runtime checks and releases a
// mutable reference if it's safe to do so (or panics).
self.inner.borrow_mut().intern(value)
}
fn lookup(&self, id: usize) -> Rc<String> {
self.inner.borrow().lookup(id)
}
}
With this setup, we can for example overload the comparison operator == to directly compare interned strings with regular strings.
impl PartialEq<String> for IString<'_> {
fn eq(&self, other: &String) -> bool {
self.lookup().deref() == other
}
}
Lastly, I’ve defined new structs for the data schema using the interned string type in place of all strings.
This means adding a lifetime 'a everywhere, which isn’t quite ergonomic, but we’ll revisit this pattern later.
struct Disruption<'a> {
id: IString<'a>,
application_periods: Vec<ApplicationPeriod<'a>>,
last_update: IString<'a>,
cause: IString<'a>,
severity: IString<'a>,
tags: Option<Vec<IString<'a>>>,
title: IString<'a>,
message: IString<'a>,
disruption_id: Option<IString<'a>>,
}
struct ApplicationPeriod<'a> {
begin: IString<'a>,
end: IString<'a>,
}
I’ve also defined functions to convert data from the original structs to their interned counterparts, as well as comparison functions to validate that the interned data is semantically equivalent to the original (and confirm that my benchmarks are not cheating).
impl<'a> ApplicationPeriod<'a> {
fn from(interner: &'a StringInterner, source: source::ApplicationPeriod) -> Self {
Self {
begin: IString::from(interner, source.begin),
end: IString::from(interner, source.end),
}
}
}
impl PartialEq<source::ApplicationPeriod> for ApplicationPeriod<'_> {
fn eq(&self, other: &source::ApplicationPeriod) -> bool {
self.begin == other.begin && self.end == other.end
}
}
With that, we can already see the effectiveness of interning: each string appeared on average 425 times in the input data, the in-memory data is three times smaller than the baseline, and twice smaller than the original JSON files (commit 5297faa). We’re still quite far from the headline of this post though!
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Optimized to 529308335 bytes (relative size = 46.55%)
- [0.84%] String interner: 56374 objects | 4433343 bytes (78.64 bytes/object) | 23964083 references (425.09 refs/object)
Arbitrary types (7.6%)
The next step was to realize that strings aren’t the only objects that repeat a lot in the input data.
For example, a Disruption may last maybe an hour if it’s unexpected, or something like a month if it’s planned maintenance work.
Given that the input data is a time series sampled every 2 minutes, it’s expected that a given disruption will show up many times.
Fortunately, the interning technique isn’t unique to strings: any data that can be put into a vector and a hash map should work as well.
So we can use generics to make it work for arbitrary types that implement Eq and Hash (to work with a hash map).
// Type alias for convenience.
type IString<'a> = Interned<'a, String>;
struct Interned<'a, T> {
interner: &'a Interner<T>,
id: usize,
}
impl<'a, T: Eq + Hash> Interned<'a, T> {
fn from(interner: &'a Interner<T>, value: T) -> Self {
let id = interner.intern(value);
Self { interner, id }
}
fn lookup(&self) -> Rc<T> {
self.interner.lookup(self.id)
}
}
As a new requirement, we also need to implement the PartialEq, Eq and Hash traits on Interned<_>, so that it can be recursively used in structs that are themselves interned.
A naive implementation is to lookup the actual data and compare or hash it, but we’ll revisit that in a moment.
use std::hash::{Hash, Hasher};
impl<T: Eq + Hash> PartialEq for Interned<'_, T> {
fn eq(&self, other: &Self) -> bool {
self.lookup().deref() == other.lookup().deref()
}
}
impl<T: Eq + Hash> Eq for Interned<'_, T> {}
impl<T: Eq + Hash> Hash for Interned<'_, T> {
fn hash<H>(&self, state: &mut H)
where
H: Hasher,
{
self.lookup().deref().hash(state)
}
}
On the schema side, we’ll now have a collection of interners: each type gets its own interner.
#[derive(Default)]
struct Interners<'a> {
string: Interner<String>,
disruption: Interner<Disruption<'a>>,
line: Interner<Line<'a>>,
application_period: Interner<ApplicationPeriod<'a>>,
impacted_object: Interner<ImpactedObject<'a>>,
}
The data structs in the schema can now contain interned versions of other structs, such as Interned<'a, ApplicationPeriod<'a>>, and simply derive the comparison and hashing traits.
#[derive(Debug, Hash, PartialEq, Eq)]
struct Disruption<'a> {
id: IString<'a>,
application_periods: Vec<Interned<'a, ApplicationPeriod<'a>>>,
last_update: IString<'a>,
cause: IString<'a>,
severity: IString<'a>,
tags: Option<Vec<IString<'a>>>,
title: IString<'a>,
message: IString<'a>,
disruption_id: Option<IString<'a>>,
}
Conversion from the original data types now uses a reference to the whole collection of Interners.
impl<'a> Disruption<'a> {
fn from(interners: &'a Interners<'a>, source: source::Disruption) -> Self {
Self {
id: Interned::from(&interners.string, source.id),
application_periods: source
.application_periods
.into_iter()
.map(|x| {
Interned::from(
&interners.application_period,
ApplicationPeriod::from(interners, x),
)
})
.collect(),
...
}
}
}
With this generalization, the size improvement starts to be substantial, about 6 times smaller than the previous step and 12 times smaller than the baseline input files (commit f532ef9).
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Optimized to 86349519 bytes (relative size = 7.59%)
[67.50%] Interners: 58288479 bytes
- [5.13%] String interner: 56374 objects | 4433343 bytes (78.64 bytes/object) | 23964083 references (425.09 refs/object)
- [1.81%] Disruption interner: 7550 objects | 1565896 bytes (207.40 bytes/object) | 625760 references (82.88 refs/object)
- [0.28%] ApplicationPeriod interner: 5883 objects | 245688 bytes (41.76 bytes/object) | 631593 references (107.36 refs/object)
- [53.61%] Line interner: 97090 objects | 46289464 bytes (476.77 bytes/object) | 930026 references (9.58 refs/object)
- [6.66%] ImpactedObject interner: 56110 objects | 5754088 bytes (102.55 bytes/object) | 3183332 references (56.73 refs/object)
Dropping the reference (2.8%)
One thing you may have noticed is how the reference to an Interner proliferates well beyond the Interned struct.
It forces us (1) to add a lifetime 'a everywhere and (2) to use interior mutability which causes the Interner/InternerImpl split.
struct Interned<'a, T> {
interner: &'a Interner<T>,
id: usize,
}
Crucially, it also means inflated memory usage due to a lot of duplication: a struct like Disruption<'a> contains at least 7 references to the same string interner!
So what if we just got rid of it?
In the current design, the Interned type is intrusive (as it’s aware of the surrounding Interner).
We can instead externalize the interner, and let the caller provide a reference to the interner when needed.
use std::marker::PhantomData;
struct Interned<T> {
id: usize,
// Marker to indicate that an interned object behaves like a function that
// returns a T (via the lookup method).
_phantom: PhantomData<fn() -> T>,
}
impl<T: Eq + Hash> Interned<T> {
// The interner reference is now provided by the caller.
fn from(interner: &Interner<T>, value: T) -> Self {
interner.intern(value)
}
// Same here.
fn lookup(&self, interner: &Interner<T>) -> Rc<T> {
interner.lookup(self.id)
}
}
One difficulty with this simplified design is how to implement comparison and hashing methods on Interned<T>.
Indeed, these operators have a fixed API given by traits such as PartialEq, so an interner reference cannot be provided as an additional value to the eq() function for example.
To solve this issue, we can remark that an interned index fully represents the underlying object (within the realm of an interner): two values will be interned to the same index if and only if they are equal.
So rather than doing a deep (recursive) comparison, we can simply compare the indices, i.e. derive their implementations for Interned.
Likewise for hashing.
#[derive(Debug, Hash, PartialEq, Eq)]
struct Interned<T> { /* ... */ }
However, the difficulty remains when we want to compare an Interned<T> with a T.
In that case, we really need to look up the underlying value and perform a deep comparison.
For that purpose, I ended up defining a new EqWith trait that allows passing the interner as a helper object for the comparison.
trait EqWith<Rhs, Helper> {
fn eq_with(&self, other: &Rhs, helper: &Helper) -> bool;
}
impl<T: Eq + Hash> EqWith<T, Interner<T>> for Interned<T> {
fn eq_with(&self, other: &T, interner: &Interner<T>) -> bool {
self.lookup(interner).deref() == other
}
}
We can then compare structs from the source and optimized schemas.
#[derive(Debug, Hash, PartialEq, Eq)]
struct ApplicationPeriod {
begin: IString,
end: IString,
}
impl EqWith<source::ApplicationPeriod, Interners> for ApplicationPeriod {
fn eq_with(&self, other: &source::ApplicationPeriod, interners: &Interners) -> bool {
self.begin.eq_with(&other.begin, &interners.string)
&& self.end.eq_with(&other.end, &interners.string)
}
}
With that, we’ve halved the size of an Interned<T>, and therefore almost halved the total in-memory size (commit 59fae78).
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Optimized to 49829943 bytes (relative size = 4.38%)
[68.66%] Interners: 34215191 bytes
- [8.90%] String interner: 56374 objects | 4433335 bytes (78.64 bytes/object) | 23964083 references (425.09 refs/object)
- [2.17%] Disruption interner: 7550 objects | 1081928 bytes (143.30 bytes/object) | 625760 references (82.88 refs/object)
- [0.30%] ApplicationPeriod interner: 5883 objects | 151552 bytes (25.76 bytes/object) | 631593 references (107.36 refs/object)
- [49.71%] Line interner: 97090 objects | 24768600 bytes (255.11 bytes/object) | 930026 references (9.58 refs/object)
- [7.59%] ImpactedObject interner: 56110 objects | 3779776 bytes (67.36 bytes/object) | 3183332 references (56.73 refs/object)
Can we half it again?
Yes!
The original blog post by matklad was using a u32 index, rather than usize.
This is indeed a fairly reasonable choice for objects that are supposed to be referenced multiple times.
In my case, the dataset didn’t contain any type with more than a million distinct objects, so there was enough margin.
struct Interned<T> {
id: u32, // Now a 32-bit index.
_phantom: PhantomData<fn() -> T>,
}
impl<T: Eq + Hash> Interner<T> {
fn intern(&mut self, value: T) -> u32 {
if let Some(&id) = self.map.get(&value) {
return id;
}
// Runtime check that the identifier doesn't exceed a u32.
let id = self.vec.len();
assert!(id <= u32::MAX as usize);
let id = id as u32;
let rc: Rc<T> = Rc::new(value);
self.vec.push(Rc::clone(&rc));
self.map.insert(rc, id);
id
}
fn lookup(&self, id: u32) -> Rc<T> {
Rc::clone(&self.vec[id as usize])
}
}
We’re now down below 3% of the original data set size (commit 84d79e7). Steady progress!
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Optimized to 31391391 bytes (relative size = 2.76%)
[72.41%] Interners: 22730967 bytes
- [14.12%] String interner: 56374 objects | 4433335 bytes (78.64 bytes/object) | 23964083 references (425.09 refs/object)
- [2.48%] Disruption interner: 7550 objects | 779548 bytes (103.25 bytes/object) | 625760 references (82.88 refs/object)
- [0.33%] ApplicationPeriod interner: 5883 objects | 104488 bytes (17.76 bytes/object) | 631593 references (107.36 refs/object)
- [45.86%] Line interner: 97090 objects | 14396532 bytes (148.28 bytes/object) | 930026 references (9.58 refs/object)
- [9.61%] ImpactedObject interner: 56110 objects | 3017064 bytes (53.77 bytes/object) | 3183332 references (56.73 refs/object)
Tuning the schema
Using general interning techniques wasn’t the end of the journey. Indeed, we can leverage business knowledge about the data to optimize it even more.
Sorting sets (1.5%)
One common pattern in this data was a field containing a set of objects (themselves interned).
For example, a Line contains a set of impacted objects stored as a Vec<Interned<ImpactedObject>>, and each ImpactedObject contains a set of disruption IDs as a Vec<IString>.
struct Line {
id: IString,
name: IString,
short_name: IString,
mode: IString,
network_id: IString,
impacted_objects: Vec<Interned<ImpactedObject>>,
}
struct ImpactedObject {
typ: IString,
id: IString,
name: IString,
disruption_ids: Vec<IString>,
}
What’s interesting is that these sets don’t have a particular order, semantically speaking: we only care about which objects are impacted on a given metro line, not whether one impacted object is “before” another (whatever that means).
However, in Rust the Vec collection type is semantically ordered!
This means that two ImpactedObjects with the same typ, id and name fields but disruption_ids equal to [123, 42, 73] in one case and [73, 123, 42] in the other would be considered different in terms of hashing and equality, even though they are semantically the same.
As it turns out, the API was returning such sets in arbitrary order from one call to the next (which I guess makes sense if they internally represent them using hash tables or hash sets). So one object containing a set of items could be represented as up to JSON representations appearing distinct from the perspective of the interner (number of permutations of items).
Unfortunately, the problem compounds: a Line contains a set of ImpactedObjects which themselves contain sets of IString.
Consider the following example: each of the two ImpactedObjects has possible representations and there are possible orderings of these two objects, so this Line has up to representations.
And that’s a fairly simple example, in reality the sets could be longer than 3 disruptions.
In practice, the Interner<Line> contained the most number of objects (97090), totaling 14 MB which was 45% of the optimized bytes.
Line {
impacted_objects: vec![
ImpactedObject {
disruption_ids: vec![1, 2, 3], ...
},
ImpactedObject {
disruption_ids: vec![4, 5, 6], ...
},
],
...
}
// Same object serialized differently.
Line {
impacted_objects: vec![
ImpactedObject {
disruption_ids: vec![6, 4, 5], ...
},
ImpactedObject {
disruption_ids: vec![2, 1, 3], ...
},
],
...
}
To mitigate this problem, we can canonicalize such sets, the easiest way being to sort them.
However, adding ordering operators (via the PartialOrd and Ord traits) for all the structs in the schema would be annoying.
But that’s not required: we only need to order sets of Interned<T>, and we can do that by simply ordering the underlying indices!
Indeed, all we need is a canonical order, we don’t care if this order reflects the semantics of the objects.
Unfortunately, we cannot derive PartialOrd on Interned<T> if the underlying T doesn’t itself implement it.
This is a known and long-standing limitation of derive (more than 10 years old!).
use std::marker::PhantomData;
#[derive(PartialEq, Eq, PartialOrd, Ord)]
struct Interned<T> {
id: u32,
_phantom: PhantomData<fn() -> T>,
}
struct MyArbitraryType;
fn foo(set: &mut [Interned<MyArbitraryType>]) {
// error[E0277]: the trait bound `MyArbitraryType: Ord` is not satisfied
set.sort_unstable();
}
error[E0277]: the trait bound `MyArbitraryType: Ord` is not satisfied
--> src/lib.rs:13:9
|
13 | set.sort_unstable();
| ^^^^^^^^^^^^^ the trait `Ord` is not implemented for `MyArbitraryType`
|
= help: the trait `Ord` is implemented for `Interned<T>`
note: required for `Interned<MyArbitraryType>` to implement `Ord`
--> src/lib.rs:3:37
|
3 | #[derive(PartialEq, Eq, PartialOrd, Ord)]
| ^^^ unsatisfied trait bound introduced in this `derive` macro
note: required by a bound in `core::slice::<impl [T]>::sort_unstable`
--> /playground/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/slice/mod.rs:2932:12
|
2930 | pub fn sort_unstable(&mut self)
| ------------- required by a bound in this associated function
2931 | where
2932 | T: Ord,
| ^^^ required by this bound in `core::slice::<impl [T]>::sort_unstable`
= note: this error originates in the derive macro `Ord` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider annotating `MyArbitraryType` with `#[derive(Ord)]`
|
9 + #[derive(Ord)]
10 | struct MyArbitraryType;
|
So we have to implement the comparison traits manually on Interned<T>, which isn’t that bad.
Note that if we implement PartialEq manually, we can derive(Hash) it but a Clippy lint will warn against that.
use std::cmp::Ordering;
use std::hash::{Hash, Hasher};
impl<T> PartialEq for Interned<T> {
fn eq(&self, other: &Self) -> bool {
self.id.eq(&other.id)
}
}
impl<T> Eq for Interned<T> {}
impl<T> PartialOrd for Interned<T> {
fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
Some(self.cmp(other))
}
}
impl<T> Ord for Interned<T> {
fn cmp(&self, other: &Self) -> Ordering {
self.id.cmp(&other.id)
}
}
impl<T> Hash for Interned<T> {
fn hash<H>(&self, state: &mut H)
where
H: Hasher,
{
self.id.hash(state);
}
}
I then chose to create an InternedSet<T> abstraction, that will sort the items in canonical order.
Note the use of the sort_unstable() function, which is more efficient than the generic sort().
Also note that we store the set as a boxed slice Box<[_]> instead of a Vec<_>, which is more compact for immutable sequences as it doesn’t require storing a capacity field to potentially grow the vector.
#[derive(Debug, Hash, PartialEq, Eq)]
struct InternedSet<T> {
set: Box<[Interned<T>]>,
}
impl<T> InternedSet<T> {
fn new(set: impl IntoIterator<Item = Interned<T>>) -> Self {
let mut set: Box<[_]> = set.into_iter().collect();
set.sort_unstable();
Self { set }
}
}
We can then integrate it into the schema as follows.
struct ImpactedObject {
typ: IString,
id: IString,
name: IString,
disruption_ids: InternedSet<String>,
}
impl ImpactedObject {
fn from(interners: &mut Interners, source: source::ImpactedObject) -> Self {
Self {
typ: Interned::from(&mut interners.string, source.typ),
id: Interned::from(&mut interners.string, source.id),
name: Interned::from(&mut interners.string, source.name),
disruption_ids: InternedSet::new(
source
.disruption_ids
.into_iter()
.map(|x| Interned::from(&mut interners.string, x)),
),
}
}
}
This change divided the number of different Line objects by 14, and the total optimized size by two once again (commit bdb00b5).
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Optimized to 16578863 bytes (relative size = 1.46%)
[50.70%] Interners: 8405895 bytes
- [26.74%] String interner: 56374 objects | 4433335 bytes (78.64 bytes/object) | 23964083 references (425.09 refs/object)
- [3.97%] Disruption interner: 7550 objects | 658748 bytes (87.25 bytes/object) | 625760 references (82.88 refs/object)
- [0.63%] ApplicationPeriod interner: 5883 objects | 104488 bytes (17.76 bytes/object) | 631593 references (107.36 refs/object)
- [4.06%] Line interner: 6880 objects | 672568 bytes (97.76 bytes/object) | 930026 references (135.18 refs/object)
- [15.30%] ImpactedObject interner: 55373 objects | 2536756 bytes (45.81 bytes/object) | 3183332 references (57.49 refs/object)
Using enums (1.4%)
At this point, the Data root structs used half of the optimized size.
You might have noticed that it contained only optional fields.
struct Data {
status_code: Option<i32>,
error: Option<IString>,
message: Option<IString>,
disruptions: Option<InternedSet<Disruption>>,
lines: Option<InternedSet<Line>>,
last_updated_date: Option<IString>,
}
However, in practice, the fields that are set come together: either the object contains an error, with status_code, error and message fields, or it contains useful data with disruptions, lines and last_updated_date fields.
So a better representation is to use an enumeration with two variants.
enum Data {
Success {
disruptions: InternedSet<Disruption>,
lines: InternedSet<Line>,
last_updated_date: IString,
},
Error {
status_code: i32,
error: IString,
message: IString,
},
}
This separation brings two benefits: the schema is more sound semantically and takes less space in memory.
Indeed, an Interned<T> uses 4 bytes (a u32 index) but an Option<Interned<T>> uses 8 bytes: 1 bit for the option state and the rest to align to a multiple of 4 bytes.
The improvement was more modest this time (commit c8ac261).
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Optimized to 15847679 bytes (relative size = 1.39%)
[53.04%] Interners: 8405895 bytes
- [27.97%] String interner: 56374 objects | 4433335 bytes (78.64 bytes/object) | 23964083 references (425.09 refs/object)
- [4.16%] Disruption interner: 7550 objects | 658748 bytes (87.25 bytes/object) | 625760 references (82.88 refs/object)
- [0.66%] ApplicationPeriod interner: 5883 objects | 104488 bytes (17.76 bytes/object) | 631593 references (107.36 refs/object)
- [4.24%] Line interner: 6880 objects | 672568 bytes (97.76 bytes/object) | 930026 references (135.18 refs/object)
- [16.01%] ImpactedObject interner: 55373 objects | 2536756 bytes (45.81 bytes/object) | 3183332 references (57.49 refs/object)
Splitting structs (0.82%)
Another thing you may have noticed about the ImpactedObject example is that it contains both fields that are constant (type, identifier, name) and fields that change over time (list of disruptions).
This means that each time a disruption is added or removed from the list, a new ImpactedObject is created and added to the interner, even if the “header” fields that define the object haven’t changed.
A more optimized approach is to extract the fixed fields into a separate object, and to add a new interner for it.
struct ImpactedObject {
// Fixed part of an object.
object: Interned<Object>,
disruption_ids: InternedSet<String>,
}
// New struct grouping the fixed fields of an object.
struct Object {
typ: IString,
id: IString,
name: IString,
}
Note that this new design doesn’t change the total number of ImpactedObjects (55373), but makes each one smaller: one u32 index for an Interned<Object> instead of three IString indices.
There are however much fewer Objects (1679) because each one is referenced by many ImpactedObjects (commit 8914a64).
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Optimized to 15330607 bytes (relative size = 1.35%)
[51.46%] Interners: 7888823 bytes
- [28.92%] String interner: 56374 objects | 4433335 bytes (78.64 bytes/object) | 23964083 references (425.09 refs/object)
- [4.30%] Disruption interner: 7550 objects | 658748 bytes (87.25 bytes/object) | 625760 references (82.88 refs/object)
- [0.68%] ApplicationPeriod interner: 5883 objects | 104488 bytes (17.76 bytes/object) | 631593 references (107.36 refs/object)
- [3.67%] Line interner: 6880 objects | 562488 bytes (81.76 bytes/object) | 930026 references (135.18 refs/object)
- [0.01%] LineHeader interner: 45 objects | 1428 bytes (31.73 bytes/object) | 930026 references (20667.24 refs/object)
- [13.66%] ImpactedObject interner: 55373 objects | 2093772 bytes (37.81 bytes/object) | 3183332 references (57.49 refs/object)
- [0.23%] Object interner: 1679 objects | 34564 bytes (20.59 bytes/object) | 3183332 references (1895.97 refs/object)
The improvement was small this time, but if we look at the second half of an ImpactedObject we can observe that several objects may be affected by the exact same set of disruptions, for example because they represent stations on the same line.
By adding another layer of indirection and interning the interned set, we can again reduce redundancy.
In practice there were only 9127 distinct sets of disruption IDs (commit fcff0d5).
struct ImpactedObject {
object: Interned<Object>,
// Also intern the set.
disruption_ids: Interned<InternedSet<String>>,
}
This reduced the optimized size by more than a third.
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1531039733 bytes in memory (relative size = 134.63%)
Optimized to 9364491 bytes (relative size = 0.82%)
[94.79%] Interners: 8877035 bytes
- [47.34%] String interner: 56374 objects | 4433335 bytes (78.64 bytes/object) | 23964083 references (425.09 refs/object)
- [3.50%] InternedSet<String> interner: 9127 objects | 327620 bytes (35.90 bytes/object) | 3183332 references (348.78 refs/object)
- [7.90%] InternedSet<Disruption> interner: 7066 objects | 739652 bytes (104.68 bytes/object) | 30430 references (4.31 refs/object)
- [7.03%] Disruption interner: 7550 objects | 658748 bytes (87.25 bytes/object) | 625760 references (82.88 refs/object)
- [1.12%] ApplicationPeriod interner: 5883 objects | 104488 bytes (17.76 bytes/object) | 631593 references (107.36 refs/object)
- [11.88%] InternedSet<Line> interner: 7183 objects | 1112896 bytes (154.93 bytes/object) | 30430 references (4.24 refs/object)
- [6.01%] Line interner: 6880 objects | 562488 bytes (81.76 bytes/object) | 930026 references (135.18 refs/object)
- [0.02%] LineHeader interner: 45 objects | 1428 bytes (31.73 bytes/object) | 930026 references (20667.24 refs/object)
- [9.63%] ImpactedObject interner: 55373 objects | 901816 bytes (16.29 bytes/object) | 3183332 references (57.49 refs/object)
- [0.37%] Object interner: 1679 objects | 34564 bytes (20.59 bytes/object) | 3183332 references (1895.97 refs/object)
Specializing types (0.64%)
After all these optimizations, strings were using half of the optimized space: each Interner is a table that other objects can reference by index.
In practice, the string interner contained values of very heterogeneous semantics: some strings were long error messages in HTML format, some were simple names of places, some were identifiers such as UUIDs and others were timestamps in human-readable format.
The latter two are particularly interesting: instead of storing them as plain strings, we could parse them into more compact and semantically rich formats.
For UUIDs, we can simply use the Uuid type from the uuid crate as a drop-in replacement.
Internally, this type uses only 16 bytes to store each identifier, instead of 36 bytes for strings like 67e55044-10b1-426f-9247-bb680e5fe0c8 (overhead of hexadecimal encoding + separators).
For timestamps, I opted for the chrono crate, aiming to store each one in 8 bytes (64-bit number of seconds since the Unix epoch) rather than 15 to 24 bytes for something like 20240428T044500 or 2024-05-01T00:59:25.384Z.
There was a difficulty however: some timestamps were encoded in RFC 3339 format with millisecond precision in the UTC time zone, others were a naive date + time in seconds implicitly in the Paris time zone.
In that case, I used the chrono-tz crate to handle the conversion and canonicalize them to UTC.
There is a caveat however when the time zone is implicit: on days when daylight saving starts or end, the times between 2am and 3am may either be ambiguous (we don’t know if we’re in the CET or CEST time zone when the time jumps back from 3am to 2am) or invalid (when the time jumps from 2am to 3am). That said, the metro network is normally closed at this time, so a small imprecision isn’t too dramatic. It would be more annoying for the scheduling of night trains for example.
use chrono::offset::LocalResult;
use chrono::{DateTime, NaiveDateTime};
use chrono_tz::Europe::Paris;
struct TimestampSecondsParis(i64);
impl TimestampSecondsParis {
fn from_formatted(x: &str, format: &str) -> Self {
let naive_datetime = NaiveDateTime::parse_from_str(x, format).unwrap_or_else(|_| {
panic!("Failed to parse datetime (custom format {format:?}) from {x}")
});
// Handle the specifics of times falling during the daylight saving transition.
let datetime = match naive_datetime.and_local_timezone(Paris) {
LocalResult::Single(x) => x,
LocalResult::Ambiguous(earliest, latest) => {
eprintln!("Ambiguous mapping of {naive_datetime:?} to the Paris timezone: {earliest:?} or {latest:?}");
earliest
}
LocalResult::None => {
panic!("Invalid mapping of {naive_datetime:?} to the Paris timezone")
}
};
TimestampSecondsParis(datetime.timestamp())
}
}
These changes removed a large majority of the interned strings, shaving off another 2 MB (commits 2031f42 and ad29181).
Parsed 1137178883 bytes from 30466 files (+ 21 failed files)
Expanded to 1322690141 bytes in memory (relative size = 116.31%)
Optimized to 7264110 bytes (relative size = 0.64%)
[89.93%] Interners: 6532926 bytes
- [25.03%] String interner: 8050 objects | 1818466 bytes (225.90 bytes/object) | 17309489 references (2150.25 refs/object)
- [2.25%] Uuid interner: 6617 objects | 163296 bytes (24.68 bytes/object) | 4735218 references (715.61 refs/object)
- [10.18%] InternedSet<Disruption> interner: 7066 objects | 739652 bytes (104.68 bytes/object) | 30430 references (4.31 refs/object)
- [9.90%] Disruption interner: 7550 objects | 719148 bytes (95.25 bytes/object) | 625760 references (82.88 refs/object)
- [2.09%] ApplicationPeriod interner: 5883 objects | 151552 bytes (25.76 bytes/object) | 631593 references (107.36 refs/object)
- [15.32%] InternedSet<Line> interner: 7183 objects | 1112896 bytes (154.93 bytes/object) | 30430 references (4.24 refs/object)
- [7.74%] Line interner: 6880 objects | 562488 bytes (81.76 bytes/object) | 930026 references (135.18 refs/object)
- [0.02%] LineHeader interner: 45 objects | 1428 bytes (31.73 bytes/object) | 930026 references (20667.24 refs/object)
- [12.41%] ImpactedObject interner: 55373 objects | 901816 bytes (16.29 bytes/object) | 3183332 references (57.49 refs/object)
- [0.48%] Object interner: 1679 objects | 34564 bytes (20.59 bytes/object) | 3183332 references (1895.97 refs/object)
- [4.51%] InternedSet<Uuid> interner: 9127 objects | 327620 bytes (35.90 bytes/object) | 3183332 references (348.78 refs/object)
Serialization
At this point, we basically have an implicit in-memory database. The next step is to serialize it, to see how interning plays out with persistence. Serialization is also an important step to validate that the claimed space improvements are real. Lastly, it’s an opportunity to further compress the data.
In Rust, the de-facto serialization framework is serde, which we’ve already used to import the JSON input.
Serde supports many formats out-of-the-box, via extension crates, so I’ve decided to try a few of them.
- CBOR, via
ciborium, - JSON, via
serde_json, - Postcard, via
postcard, - The
bincodecrate (no specification available).
Writing custom (de)serializers with Serde (0.29%)
Usually, all you have to do is to annotate each type in your schema with #[derive(Serialize, Deserialize)] and Serde provides you (de)serialization functions out-of-the-box, which is the whole appeal of the framework.
However, this wouldn’t be very efficient for the Interner<T> table, which contains the same objects twice (in a vector and in a hash map).
Additionally, Serde’s documentation mentions that even though Rc is (de)serializable if you opt into the rc feature, it copies the underlying content each time it’s referenced, which isn’t optimal nor semantically equivalent.
struct Interner<T> {
vec: Vec<Rc<T>>,
map: HashMap<Rc<T>, u32>,
}
In this case, we don’t want to serialize both the vector of objects and the lookup table of indices: the whole interner state can be recovered from the vector alone. Indeed, if we deserialize the objects in the same order, they will get the same indices. And hopefully, Serde makes it easy to serialize a sequence.
Indeed, the docs for Serialize and Serializer quickly guide us to a solution, namely the serialize_seq() or collect_seq() methods (the latter works well with functional-style iterators).
use serde::{Serialize, Serializer};
impl<T: Serialize> Serialize for Interner<T> {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
// Tell Serde to serialize a sequence of items.
serializer.collect_seq(self.vec.iter().map(|rc| rc.deref()))
}
}
Deserialization is more complex, which isn’t surprising as it needs to handle potential errors in the serialized stream. Ultimately, you need to check the guide directly on Serde’s website, as the regular API documentation doesn’t explain the details.
One needs not only to manipulate the Deserialize and Deserializer traits, but also write a Visitor and (in this case) manipulate a SeqAccess.
There’s a lot more boilerplate, but it works out.
use serde::de::{SeqAccess, Visitor};
use serde::{Deserialize, Deserializer};
impl<'de, T> Deserialize<'de> for Interner<T>
where
T: Eq + Hash + Deserialize<'de>,
{
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: Deserializer<'de>,
{
// Tell Serde to deserialize a sequence of items using the given visitor.
deserializer.deserialize_seq(InternerVisitor::new())
}
}
// A visitor to create an Interner<T>.
struct InternerVisitor<T> {
// This visitor is stateless, but Rust requires to use the generic parameter T.
_phantom: PhantomData<fn() -> Interner<T>>,
}
impl<T> InternerVisitor<T> {
fn new() -> Self {
Self {
_phantom: PhantomData,
}
}
}
impl<'de, T> Visitor<'de> for InternerVisitor<T>
where
T: Eq + Hash + Deserialize<'de>,
{
// Tell Serde that the output will be an Interner.
type Value = Interner<T>;
// Error message to display if the input stream doesn't contain a sequence of Ts.
fn expecting(&self, formatter: &mut std::fmt::Formatter) -> std::fmt::Result {
formatter.write_str("a sequence of values")
}
// Callback invoked by Serde with a sequence of items.
fn visit_seq<A>(self, mut seq: A) -> Result<Self::Value, A::Error>
where
A: SeqAccess<'de>,
{
// Serde may give us a hint about the number of items in the sequence.
let mut interner = match seq.size_hint() {
None => Interner::default(),
Some(size_hint) => Interner {
vec: Vec::with_capacity(size_hint),
map: HashMap::with_capacity(size_hint),
references: 0,
},
};
// We gather the elements in a loop and return an Interner.
while let Some(t) = seq.next_element()? {
interner.push(t);
}
Ok(interner)
}
}
// For completeness, here is the new push() function, slightly more efficient than intern().
impl<T: Eq + Hash> Interner<T> {
/// Unconditionally push a value, without validating that it's already interned.
fn push(&mut self, value: T) -> u32 {
let id = self.vec.len();
assert!(id <= u32::MAX as usize);
let id = id as u32;
let rc: Rc<T> = Rc::new(value);
self.vec.push(Rc::clone(&rc));
self.map.insert(rc, id);
id
}
}
Here is a comparison of the serialization formats at this point, sorted by encoded size. Postcard is a clear winner at 3.2 MB, much less than JSON at 65 MB in pretty-printed form or 26 MB in minified form (commit b5013e6).
| Format | Bytes | Relative size | Encode time | Decode time |
|---|---|---|---|---|
| Postcard | 3275869 | 0.29% | 17 ms | 16 ms |
| Bincode | 5437330 | 0.48% | 16 ms | 24 ms |
| CBOR | 17484567 | 1.54% | 56 ms | 128 ms |
| JSON | 26485131 | 2.33% | 74 ms | 118 ms |
| JSON (pretty) | 65026281 | 5.72% | 152 ms | 135 ms |
It’s also interesting to compare the encoding and decoding times, as the more compact formats tend to be faster to process too.
Take them with a grain of salt though, that’s not a proper benchmark but a single data point on my machine, and without using any optimized library like simd_json.
Compression and fighting the Rust borrow checker Linux pipes (0.05%)
Once we have serialized the database into bytes, we can apply general-purpose compression to it. Indeed, even after interning we expect some amount of redundancy: for example disruption messages follow templates where only some details vary.
I didn’t really want to investigate the various Rust compression libraries, as I thought that spawning a command would be simpler for this experiment.
Indeed, the Command type in the Rust standard library allows to easily run other programs, passing them arguments and inputs in a safe way, and collecting the output.
In principle, one should configure Stdio::piped() to interact with stdin/stdout/stderr of the child process, and we’re good to go… or so I thought.
// Naive implementation, which doesn't work (inter-process deadlock).
fn gzip_compress(input: &[u8]) -> Result<Vec<u8>, Box<dyn std::error::Error>> {
let compress = Command::new("gzip")
.arg("-c") // Compress to stdout.
.arg("-6") // Compression level.
.stdin(Stdio::piped())
.stdout(Stdio::piped())
.stderr(Stdio::null())
.spawn()?;
compress.stdin.as_mut().expect("Failed to open stdin").write_all(input)?;
let output = compress.wait_with_output()?;
if !output.status.success() {
/* Return an error */
}
Ok(output.stdout)
}
Indeed, while this naive implementation worked for simple examples with a short input, it seemingly deadlocked once I tried to compress larger inputs!
The answer lies in the Linux manual for pipes. When a parent and child process communicate via stdin/stdout/stderr, this is done via a so-called pipe. Under the hood, the kernel provides a buffer where one process can write and the other process can read.
However, to avoid exhausting the system resources, this buffer has a limited size.
In particular, /proc/sys/fs/pipe-max-size sets the maximum size (in bytes) of one pipe, which is 1 MiB on my system.
Additionally, /proc/sys/fs/pipe-user-pages-hard and /proc/sys/fs/pipe-user-pages-soft set the maximum number of pages that one user can create in terms of pipes (across all its processes), which is 64 MiB on my system.
$ cat /proc/sys/fs/pipe-max-size
1048576
$ cat /proc/sys/fs/pipe-user-pages-hard
0
$ cat /proc/sys/fs/pipe-user-pages-soft
16384
Back to invoking gzip: the problem is that if the input is too large, the write_all(input) call will be blocked until the child (gzip) process reads from the pipe.
The gzip process will indeed start reading from it, but will also want to write compressed output as soon as possible to its standard output (to limit its own memory usage).
However, with the naive implementation, my parent process isn’t reading this output yet until it’s done writing all the input.
So the compressed output will fill its pipe too.
 Linux pipes around a compression process.
Linux pipes around a compression process.
At some point, we’ll end up in a situation where my parent process is blocked on writing more input to the stdin pipe (waiting for gzip to read it) while the child gzip process is blocked on writing more compressed output to the stdout pipe (waiting for the parent process to read it). In other words: an inter-process deadlock!
 Full pipes causing a deadlock.
Full pipes causing a deadlock.
Be really careful about this limitation: even if you think that you won’t need to write more than 1 MiB (or whatever /proc/sys/fs/pipe-max-size says on your system), the total per-user limit may restrict pipes to only one page (once /proc/sys/fs/pipe-user-pages-soft is reached) which is usually 4 KiB, i.e. much lower than the 1 MiB default.
To remediate that, we need to make sure to both write uncompressed input and read compressed output at the same time, i.e. use threads.
We can still use the convenient functions write_all() and read_to_end() as long as they happen in parallel threads.
I ended up creating a utility function to automate this pattern of writing all of an input slice and reading all of the output.
Note the use of std::thread::scope(), which allows to capture an input slice with non-static lifetime.
#![feature(exit_status_error)]
fn io_command(mut child: Child, input: &[u8]) -> Result<Vec<u8>, Box<dyn std::error::Error>> {
std::thread::scope(|s| -> Result<Vec<u8>, Box<dyn std::error::Error>> {
let mut stdin = child.stdin.take().expect("Failed to open stdin");
let mut stdout = child.stdout.take().expect("Failed to open stdout");
let input_thread = s.spawn(move || -> std::io::Result<()> {
eprintln!("Writing {} bytes...", input.len());
stdin.write_all(input)?;
drop(stdin);
Ok(())
});
let output_thread = s.spawn(move || -> std::io::Result<Vec<u8>> {
eprintln!("Reading bytes...");
let mut output = Vec::new();
stdout.read_to_end(&mut output)?;
Ok(output)
});
eprintln!("Waiting for child...");
child.wait()?.exit_ok()?;
input_thread.join().expect("Failed to join input thread")?;
let output = output_thread
.join()
.expect("Failed to join output thread")?;
Ok(output)
})
}
Back to the original topic, I’ve benchmarked a few common compression algorithms. What they show is that the size difference between formats tends to get smaller after compression. At this point, we’ve reached the 2000x size reduction mark on the most compact formats: from 1.1 GB down to 530 KB for the May 2024 data (commit b7281f5).

| Format | Serialization | gzip -6 | brotli -6 | xz -6 | ||||
|---|---|---|---|---|---|---|---|---|
| Postcard | 3275869 | 0.29% | 861917 | 0.08% | 721120 | 0.06% | 539200 | 0.05% |
| Bincode | 5437330 | 0.48% | 893271 | 0.08% | 700194 | 0.06% | 529996 | 0.05% |
| CBOR | 17484567 | 1.54% | 1187575 | 0.10% | 826739 | 0.07% | 615124 | 0.05% |
| JSON | 26485131 | 2.33% | 1253219 | 0.11% | 916683 | 0.08% | 736036 | 0.06% |
| JSON (pretty) | 65026281 | 5.72% | 1563418 | 0.14% | 1006035 | 0.09% | 958624 | 0.08% |
However, similar sizes after compression doesn’t mean you should use JSON and forget about it: (de)serialization and (de)compression speed are faster with the more optimized formats like Postcard!

| Format | Serialization | gzip -6 | brotli -6 | xz -6 | ||||
|---|---|---|---|---|---|---|---|---|
| encode | decode | encode | decode | encode | decode | encode | decode | |
| Postcard | 22 ms | 27 ms | 88 ms | 21 ms | 144 ms | 18 ms | 583 ms | 37 ms |
| Bincode | 9 ms | 24 ms | 166 ms | 28 ms | 191 ms | 19 ms | 1111 ms | 39 ms |
| CBOR | 72 ms | 131 ms | 189 ms | 63 ms | 230 ms | 36 ms | 3255 ms | 51 ms |
| JSON | 72 ms | 100 ms | 233 ms | 96 ms | 449 ms | 44 ms | 3314 ms | 60 ms |
| JSON (pretty) | 137 ms | 129 ms | 376 ms | 180 ms | 441 ms | 74 ms | 2934 ms | 81 ms |
Another aspect that was out of scope for my experiment is the impact on code size: I expect the simpler formats to also compile to smaller code. Be mindful of it especially if you’re deploying code for embedded systems or to WebAssembly for a website.
Tuple encoding
Upon inspecting the serialized outputs more closely, I noticed that a lot of _phantom strings were present in the JSON or CBOR outputs.
{"id": 11, "_phantom": null}
Something like Interned<T> which I would expect to be serialized as a simple integer was taking much more space.
struct Interned<T> {
id: u32,
_phantom: PhantomData<fn() -> T>,
}
Indeed, by default Serde serializes each struct as a map, which causes two problems:
- field names are serialized as keys in a map,
- zero-sized types like
PhantomDataare serialized even though they don’t contain any information and should be trivial to re-create.
This default might be useful if your types evolve over time (fields added, removed or renamed) and you want to retain some level of “out-of-the-box” compatibility, but that’s a design choice2.
In my case however, the Interned<T> abstraction was so ubiquitous that it meant a lot of redundancy.
After digging into it, I found these issues as well as this discussion by the maintainer of Serde, which boiled down to serializing a struct as a tuple rather than as a map.
Given that tuples don’t have field names, that should address the problem.
This feature request never got implemented in the serde crate itself, but a separate serde_tuple crate provides the Serialize_tuple and Deserialize_tuple derive macros.
use serde_tuple::{Deserialize_tuple, Serialize_tuple};
#[derive(Serialize_tuple, Deserialize_tuple)]
struct Interned<T> {
id: u32,
_phantom: PhantomData<fn() -> T>,
}
This mitigated the first issue (commits a9924e9 and cec5359).
However, the PhantomData still appeared in the serialized output as a null value.
[11, null]
Given how ubiquitous the Interned type is, I ended up writing a custom serializer once again.
impl<T> Serialize for Interned<T> {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
serializer.serialize_u32(self.id)
}
}
For the affected formats (CBOR and JSON), these optimizations reduced the encoded size by 72% to 75%. The reduction was more modest after compression, ranging from 11% to 33% (commit 356bc0a).

| Format | Serialization | gzip -6 | brotli -6 | xz -6 |
|---|---|---|---|---|
| Postcard | 3275869 | 861917 | 721120 | 539200 |
| Bincode | 5437330 | 893271 | 700194 | 529996 |
| CBOR | 4475821 (-74%) | 955541 (-20%) | 731878 (-11%) | 535068 (-13%) |
| JSON | 6560658 (-75%) | 1005689 (-20%) | 777507 (-15%) | 545832 (-26%) |
| JSON (pretty) | 18168838 (-72%) | 1162250 (-26%) | 890102 (-12%) | 639072 (-33%) |
Note that formats like Postcard and Bincode already perform this optimization by default, leveraging the fact that they are not self-describing.
By using the serde_tuple crate, you drop part of the self-describing guarantees for other formats like JSON too, as the sender and receiver must agree on the schema (e.g. the specific order of fields in each struct) to be able to communicate without data corruption.
Optimizing sets revisited
I’ve previously described how sets of objects could be better unified by sorting them.
The naive (default) approach to serialize them is a list of interned IDs.
However, in practice these IDs are often sequential, because the underlying objects were created around the same time.
For example, all the disruptions that happened on the same day would appear next to each other in the Interned<Disruption> table.
[0, 70, 72, 73, 74, 75, 77, 78, 79, 80, 81]
So instead of serializing the IDs directly, we can use delta encoding: serializing each ID as the difference from the previous ID.
[0, 70, 2, 1, 1, 1, 2, 1, 1, 1, 1]
This is beneficial for two reasons:
- common serialization formats use variable-length encoding, meaning that small numbers are encoded in fewer bytes than larger numbers,
- if most of these differences are small numbers, there should be more redundancy that the compression algorithms should be able to exploit.
As a custom Serde serializer, delta encoding is fairly straightforward to implement within each set.
struct InternedSet<T> {
set: Box<[Interned<T>]>,
}
impl<T> Serialize for InternedSet<T> {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
let mut prev = 0;
serializer.collect_seq(self.set.iter().map(|x| {
let id = x.id();
let diff = id - prev;
prev = id;
diff
}))
}
}
While differential encoding didn’t affect the Bincode format (which encodes integers with a fixed size), the serialized size decreased by 9% to 19% for the others. The size after compression saw a marked decrease (8% to 16%) with gzip and brotli, and a more modest one (4% to 8%) with xz (commit 4ea388f).

| Format | Serialization | gzip -6 | brotli -6 | xz -6 |
|---|---|---|---|---|
| Postcard | 2966573 (-9%) | 746478 (-13%) | 624801 (-13%) | 499524 (-7%) |
| Bincode | 5437330 (=) | 821573 (-8%) | 631655 (-10%) | 506956 (-4%) |
| CBOR | 3688285 (-18%) | 814306 (-15%) | 634705 (-13%) | 493064 (-8%) |
| JSON | 5317810 (-19%) | 841046 (-16%) | 708651 (-9%) | 504196 (-7%) |
| JSON (pretty) | 15018136 (-17%) | 988869 (-15%) | 820774 (-8%) | 590380 (-7%) |
In practice, we can go one step further: not only were the deltas often small, but they were also often 1s, with long sequences of consecutive elements. So I decided to add run-length encoding on top. Note that because the IDs have been sorted, the deltas are guaranteed to be non-negative, making a simple dual delta/RLE encoding possible: interpret a negative number as a run of consecutive elements, and a non-negative number as a delta from the previous element.
original: [0, 70, 72, 73, 74, 75, 77, 78, 79, 80, 81]
optimized: [0, 70, 2, -3, 2, -4]
impl<T> Serialize for InternedSet<T> {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
// Combined delta + RLE encoding.
let mut rle_encoded = Vec::with_capacity(self.set.len());
let mut prev: Option<u32> = None;
let mut streak: i32 = 0;
for x in &self.set {
let id = x.id();
let diff = id - prev.unwrap_or(0);
if prev.is_some() && diff == 1 {
streak += 1;
} else {
if streak != 0 {
rle_encoded.push(-streak);
streak = 0;
}
rle_encoded.push(diff as i32);
}
prev = Some(id);
}
if streak != 0 {
rle_encoded.push(-streak);
}
serializer.collect_seq(rle_encoded)
}
}
This last optimization gave mixed results: while the encoded size decreased by 4% to 11%, the compressed size remained similar – within ±2% (commit d098356).

| Format | Serialization | gzip -6 | brotli -6 | xz -6 |
|---|---|---|---|---|
| Postcard | 2832574 (-5%) | 751517 (+1%) | 632425 (+1%) | 504388 (+1%) |
| Bincode | 4855254 (-11%) | 825177 (+0%) | 643860 (+2%) | 516736 (+2%) |
| CBOR | 3539237 (-4%) | 813895 (-0%) | 637836 (+0%) | 495860 (+1%) |
| JSON | 5103171 (-4%) | 846290 (+1%) | 714886 (+1%) | 510584 (+1%) |
| JSON (pretty) | 13361128 (-11%) | 983777 (-1%) | 823720 (+0%) | 587044 (-1%) |
Final result: a lightweight append-only database
To reproduce these results, you’ll find my code on GitHub.
I’ve used the RATP Status data at commit ef028cc (files in the datas/json/ folder).
git init
git remote add origin https://github.com/wincelau/ratpstatus
git fetch --depth 1 origin ef028cce567b6ce9183a185e699206e0f483b99d
git checkout FETCH_HEAD
Conceptually, interning is a simple technique, yet we’ve seen that it can lead to many choices and optimizations. It’s commonly applied to strings, but in practice what really made a difference was broadly interning all sorts of data structures!
At the end of this article, we have implicitly built one of the simplest relational database designs (without all the querying/SQL part). It comes a few limitations, which are fine for a time series:
- append-only: we can’t modify nor delete existing objects,
- in-memory: the serialized form doesn’t support random access of a value at an arbitrary index, so we need to deserialize the whole database in memory,
- single-writer: to increment the index when interning a new object without synchronization.
Something that should be fairly simple to add is supporting incremental updates: given that the interning tables are append-only with incremental indices, you could easily take a snapshot of the database and later create a diff containing only the new objects added since the snapshot. Multiple reader nodes could then be implemented on top of that, which would give us a replicated database: the writer would broadcast incremental updates to the readers from time to time.
Now, practically, should you use one of the countless existing interning crates, or write it yourself? The answer is that it depends on what you’re doing!
Do you care about a very optimized in-memory layout for strings?
The naive Rc<String> representation I’ve shown may not be ideal.
Are you fine with a single global interner or do you want to manipulate local interner arenas like I’ve shown in this post?
Do you need to serialize your data, and if so should the serialization be compact?
You might even have come up with the interning pattern yourself without knowing it had a name nor that plenty of libraries implement it: that’s perfectly fine too! Hopefully this post can help you evaluate the existing libraries and make an informed decision to reinvent the wheel or not.
Appendix: optimizing the interning function
Some folks on Reddit have suggested two ways to improve the interning implementation.
- watsonborn recommended using the
HashMap::entry()API, to avoid looking up a value twice when inserting it into the interner. - angelicosphosphoros recommended using
Rc<str>rather thanRc<String>to manipulate strings.
To be clear, this article wasn’t about creating a production-ready interning library as it focused primarily on the size savings, but how to implement these recommendations is an interesting question.
Regarding the first one, using HashMap::entry() directly wouldn’t be optimal, as it requires passing a fully-fledged key, i.e. to always create a Rc<T> even when we just perform a lookup (where passing &T would be sufficient).
impl<T: Eq + Hash> Interner<T> {
fn intern(&mut self, value: T) -> u32 {
// The entry() function requires creating an Rc<T>.
let rc: Rc<T> = Rc::new(value);
*self.map.entry(Rc::clone(&rc)).or_insert_with(|| {
let id = self.vec.len();
assert!(id <= u32::MAX as usize);
self.vec.push(rc);
id as u32
})
}
}
There is however a more efficient HashMap::raw_entry_mut() API, available under the hash_raw_entry nightly feature (or on stable Rust in the hashbrown crate).
This API allows first looking up an entry with anything the key borrows to (in our case a reference &T), and to promote it to a fully-fledged Rc<T> key later, only if the entry is empty.
That’s as optimized as a map API can get in Rust.
#![feature(hash_raw_entry)]
impl<T: Eq + Hash> Interner<T> {
fn intern(&mut self, value: T) -> u32 {
let (_, id) = self
.map
.raw_entry_mut()
// We pass a &T for the lookup here.
.from_key(&value)
.or_insert_with(|| {
let id = self.vec.len();
assert!(id <= u32::MAX as usize);
let rc: Rc<T> = Rc::new(value);
self.vec.push(Rc::clone(&rc));
// We return an Rc<T> for insertion here.
(rc, id as u32)
});
*id
}
}
Regarding the second suggestion, it’s not necessarily clear cut: while a Rc<str> takes less space in memory and avoids a level of pointer indirection, the conversion from String to Rc<str> requires cloning the whole string contents.
However, this cloning cost only applies when inserting new strings, so it should hopefully be well amortized if the same strings appear many times (which is the point of interning after all).
Alternatively, one might want to use something like the CompactStr crate (performing small string optimization) to save space in memory.
But what would it take to support Interner<str>?
We first need to add an explicit T: ?Sized bound everywhere, as the string slice str is a dynamically sized type.
The second thing is that we cannot call a function with a plain T = str parameter, because it’s dynamically sized.
Instead, we can for example leverage the Borrow and Into conversion traits to create a more flexible generic API.
Combining the two suggestions, the interning function becomes the following.
Rather than taking a T, it accepts any parameter that (1) can be borrowed as a &T (to look it up in the map) and (2) can be converted into an Rc<T> (to insert it in the map).
impl<T: ?Sized + Eq + Hash> Interner<T> {
fn intern(&mut self, value: impl Borrow<T> + Into<Rc<T>>) -> u32 {
let (_, id) = self
.map
.raw_entry_mut()
// Lookup accepts any type that can be borrowed as a &T.
.from_key(value.borrow())
.or_insert_with(|| {
let id = self.vec.len();
assert!(id <= u32::MAX as usize);
let id = id as u32;
// Insertion accepts any type that can be converted to an Rc<T>.
let rc: Rc<T> = value.into();
self.vec.push(Rc::clone(&rc));
(rc, id)
});
*id
}
}
This allows passing a wide range of types to an Interner<str>: a borrowed string slice &str, an owned string String, a boxed string slice Box<str>, a copy-on-write string slice Cow<'_, str>, an Rc<str>, etc.
Beware however that converting most of these into an Rc<str> (for the insertion path) will cause a clone of the string contents.
This change also required adjustments in the size estimation and deserialization logic, I’ll let you check the details in commit 279e2cb.
This post was edited to take into account feedback on reddit, with the added appendix about a more optimized interning function.
-
And no, RATP status isn’t implemented in Rust. A PHP website can be blazingly fast too! ↩
-
In my opinion, this approach, made popular by formats like Protocol Buffers, may unfortunately give a false sense of “out-of-the-box” versioning. If you’re changing the semantics of your system, you almost always need to write additional code to ensure compatibility between the various versions. Out-of-the-box versioning can prevent outright outages in the short term, but also makes it easier to forget writing the needed compatibility code and to introduce more subtle differences due to ignoring unknown but important fields. This can cause errors, data corruption, instabilities or even other outages in the longer term. ↩
Comments
To react to this blog post please check the Mastodon thread, the Lobste.rs thread and the Reddit thread.
You may also like