Optimization adventures: making a parallel Rust workload 10x faster with (or without) Rayon
In a previous post, I’ve shown how to use the rayon framework in Rust to automatically parallelize a loop computation across multiple CPU cores.
Disappointingly, my benchmarks showed that this only provided a 2x speedup for my workload, on a computer with 8 CPU threads.
Worse, the total “user” and “system” times increased linearly with the number of threads, meaning potentially more wasted work.
Even Python was only twice slower than my Rust code, when Rust is typically 10x to 100x faster than Python.

This was the starting point of an optimization journey that led me to a 10x speed-up from this baseline. In this post, I’ll first explain which profiling tools I used to chase optimizations, before diving into how I built a faster replacement of Rayon for my use case. In the next post, I’ll describe the other optimizations that made my code much faster. Spoiler alert: copying some data sped up my code!
Wait, what? Copying data, really?! Isn’t the whole point of fighting the Rust borrow checker that you unlock super-optimized zero-copy data structures?
If you’re confused about how copying could possibly be good for performance, subscribe and stay tuned to learn why!

- Using the right profiling tools
- A hand-rolled replacement of Rayon?
- Conclusion
- Bonus: Does Rayon’s
with_max_len()help?
Using the right profiling tools
Before diving into potential optimizations, I followed the best practice of starting with profiling: this allows to see which parts of the program are a bottleneck and should be optimized, rather than making potentially incorrect assumptions and wasting time optimizing things that don’t matter. As we’ll see in the next post, this approach is not perfect either, but it should definitely be a good start.
I’m using Linux, and therefore will focus on two tools that I’ve already presented in previous posts: strace (see how to inspect a password manager) and perf (see how to profile Rust code within Docker).
A quick look at system calls
Since my benchmarks showed that the “system” time was increasing with the number of threads, a hypothesis is that Rayon wastes time making too many system calls.
So let’s start with strace to see if any system calls are prominent.
$ strace ./target/release/stv-rs <parameters>
...
futex(0x562503010900, FUTEX_WAKE_PRIVATE, 1) = 1
futex(0x7f60e525ebb4, FUTEX_WAIT_BITSET_PRIVATE, 282, NULL, FUTEX_BITSET_MATCH_ANY) = 0
futex(0x562503010908, FUTEX_WAKE_PRIVATE, 1) = 1
futex(0x562503010900, FUTEX_WAKE_PRIVATE, 1) = 1
futex(0x7f60e525ebb4, FUTEX_WAIT_BITSET_PRIVATE, 283, NULL, FUTEX_BITSET_MATCH_ANY) = 0
futex(0x7f60e525ebb4, FUTEX_WAIT_BITSET_PRIVATE, 284, NULL, FUTEX_BITSET_MATCH_ANY) = 0
...
We see a lot of futex calls, which could indicate contention on mutexes.
However, the default command only traces the main thread, which excludes the worker threads spawned by Rayon and that should do most of the work.
Using the -f flag (a.k.a. --follow-forks) to trace them shows that most background threads are calling sched_yield in a loop.
$ strace -f ./target/release/stv-rs <parameters>
...
[pid 24378] sched_yield( <unfinished ...>
[pid 24377] futex(0x7fc01c176bb4, FUTEX_WAKE_PRIVATE, 2147483647 <unfinished ...>
[pid 24376] sched_yield( <unfinished ...>
[pid 24375] sched_yield( <unfinished ...>
[pid 24374] <... sched_yield resumed>) = 0
[pid 24373] sched_yield( <unfinished ...>
...
Looking at the whole logs is not very convenient, but fortunately strace provides a summary mode with the -c flag (a.k.a. --summary-only), which can be combined with -f.
Tracing the main thread only, the highlights are:
futex– a synchronization primitive used to implement mutexes – represents the vast majority of the syscall count and time,mmap(and a couplemunmaps) is managing memory allocations1,writeprints my program’s progress and results to the standard output.
$ strace -c ./target/release/stv-rs <parameters>
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ------------------
98.80 0.269391 410 657 futex
0.31 0.000832 33 25 mmap
0.27 0.000745 53 14 mprotect
0.15 0.000406 0 657 write
0.10 0.000270 30 9 openat
0.08 0.000214 7 29 read
...
------ ----------- ----------- --------- --------- ------------------
100.00 0.272658 184 1479 9 total
Latency measurement as done by
straceis quite flaky and incurs some overhead as pointed out by Brendan Gregg, but it’s still a useful tool to get an overall idea.
Tracing all threads with -cf, the syscall time is split between futex coordination and a huge amount of sched_yield calls.
$ strace -cf ./target/release/stv-rs <parameters>
strace: Process 24423 attached
strace: Process 24424 attached
...
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ------------------
49.36 0.341755 67 5079 864 futex
48.67 0.336973 5 64938 sched_yield
0.56 0.003856 5 657 write
0.32 0.002218 54 41 mmap
0.26 0.001787 59 30 mprotect
0.17 0.001148 45 25 rt_sigprocmask
...
------ ----------- ----------- --------- --------- ------------------
100.00 0.692404 9 70926 873 total
As mentioned by Brendan Gregg, in principle
straceincurs a non-negligible overhead, and the followingperfcommand can be used to the same effect asstrace -c. However, in practice this didn’t work out-of-the-box in my profiling setup within Docker, as seemingly some special kernel filesystem needs to be mounted. I found this issue on Docker’s repository, but didn’t dig further into this as the summary insights fromstracewere good enough.$ perf stat -e 'syscalls:sys_enter_*' <binary> event syntax error: 'syscalls:sys_enter_*' \___ unknown tracepoint Error: Unable to find debugfs/tracefs Hint: Was your kernel compiled with debugfs/tracefs support? Hint: Is the debugfs/tracefs filesystem mounted? Hint: Try 'sudo mount -t debugfs nodev /sys/kernel/debug'
Time-based profiling with perf
If you’re using Linux, the most versatile profiling tool is probably the built-in perf command.
This allows to record an execution trace of a program to generate flame graphs, but also to record statistics about plenty of performance counters exposed by your CPU or the system.
A comprehensive tutorial is available on the Linux kernel Wiki, and you’ll find many examples on Brendan Gregg’s website.
I’ve previously written the important steps to make it work with Rust, which can be summarized as follows.
# Unlock profiling kernel settings if needed.
echo -1 > /proc/sys/kernel/perf_event_paranoid
echo 0 > /proc/sys/kernel/kptr_restrict
echo 0 > /proc/sys/kernel/nmi_watchdog
# Compile Rust code with frame pointers.
RUSTFLAGS='-C force-frame-pointers=y' cargo build --release
# Record a time-based profile, at the given frequency.
perf record -F <frequency> -g ./target/release/<binary>
# Spawn an interactive report in the terminal.
perf report -g graph,0.5,caller
With this interactive report, we can dig at a low level into the assembly.
- Compiling your Rust program with debug annotations can make the assembly easier to read, by showing lines of source code next to instructions.
For this, add
debug = trueto your release profile. - You can also export this assembly into the standard output via
perf annotate(see the tutorial, e.g.perf annotate -v --asm-raw --stdio).
Seeing which instructions are a bottleneck in the assembly is very low level, so at the other end of the spectrum flame graphs provide a top-down overview of where time is spent in the program.
A nice UI for that is the Firefox Profiler, which runs in the browser2 but keeps your profiles and analysis local, unless you explicitly share them.
You’ll need to transform perf record’s output using perf script, and then simply load that into the Firefox Profiler:
perf script --input=file.perf -F +pid > file.processed.perf
Once loaded, the interface shows two panels. At the top, you can see a timeline broken down by threads: yellow shows the time spent in userspace and orange in the kernel. Small blue ticks also show when stack traces were captured in each thread. From there, you can select which thread you want to focus on, to display details in the bottom panel. The default view is the “call tree”, showing a graph of functions calls grouped as a tree.
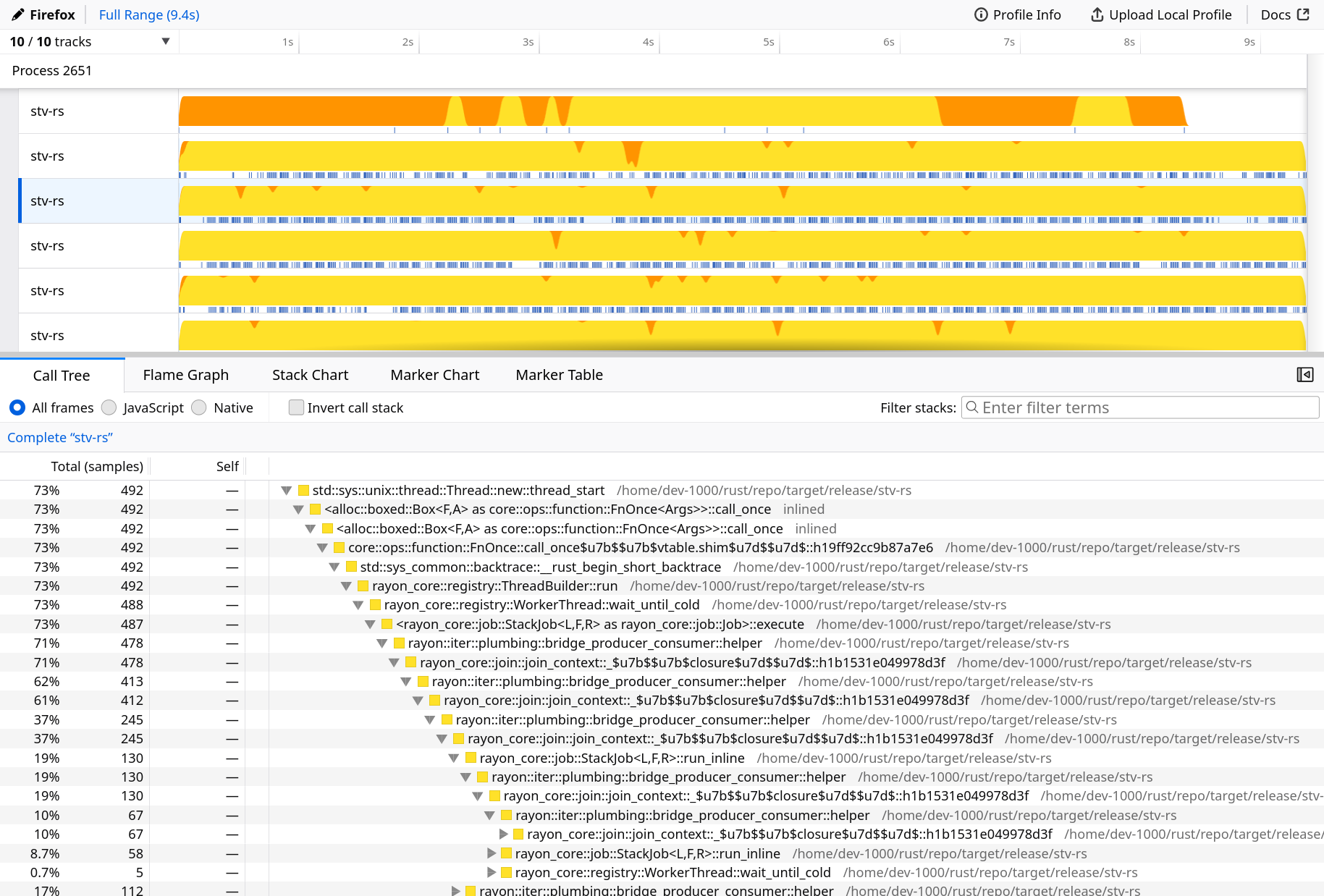 The Firefox Profiler showing the default call tree view.
The Firefox Profiler showing the default call tree view.
You may need to activate all “tracks” in the top-left corner to show all the threads.
For my Rayon workload, we can see that the main thread (top-most timeline) is mostly idle waiting for the Rayon worker threads.
The default call tree is not really useful, but shows that a lot of recursion happens between two internal functions of Rayon: bridge_producer_consumer() and join_context().
The next tab shows a flame graph, which is equivalent to a call tree but laid out from the bottom up and with the width of each node representing the total time spent in it. As you can see, it’s not very useful out-of-the-box for Rayon due to the recursion. This problem was previously reported in rayon/issues/591, and also potentially confused a user comparing Rayon with OpenMP.
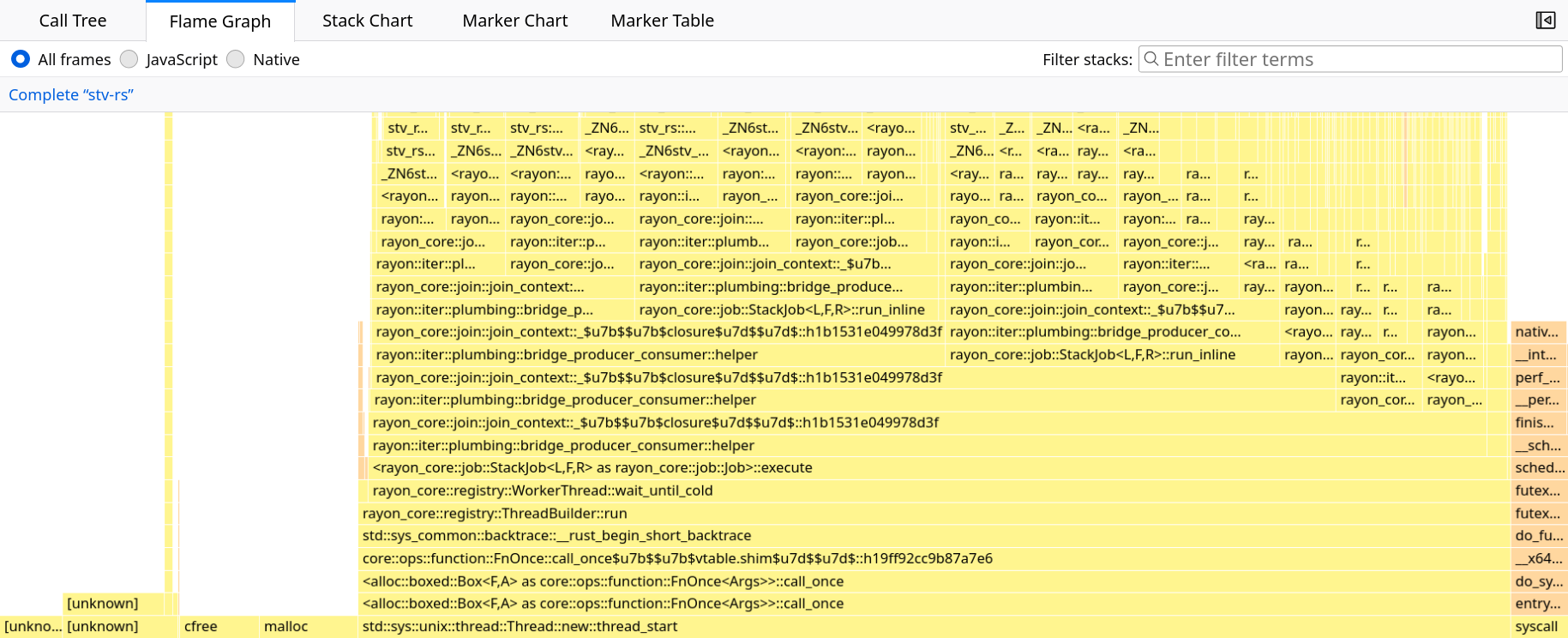 Raw flame graph in the Firefox Profiler.
Raw flame graph in the Firefox Profiler.
Fortunately, the Firefox Profiler provides a tool to alleviate that by “collapsing recursion”, accessible in the context menu by right-clicking on a node. The view is clearer: all Rayon functions are collapsed, and we can see that most of the time is spent in my ballot-counting function, at the core of the map-reduce operation that I perform with Rayon.
There’s also some non-negligible time spent in allocations, system calls (futex, as we saw above with strace), and some other unknown function from the libc.
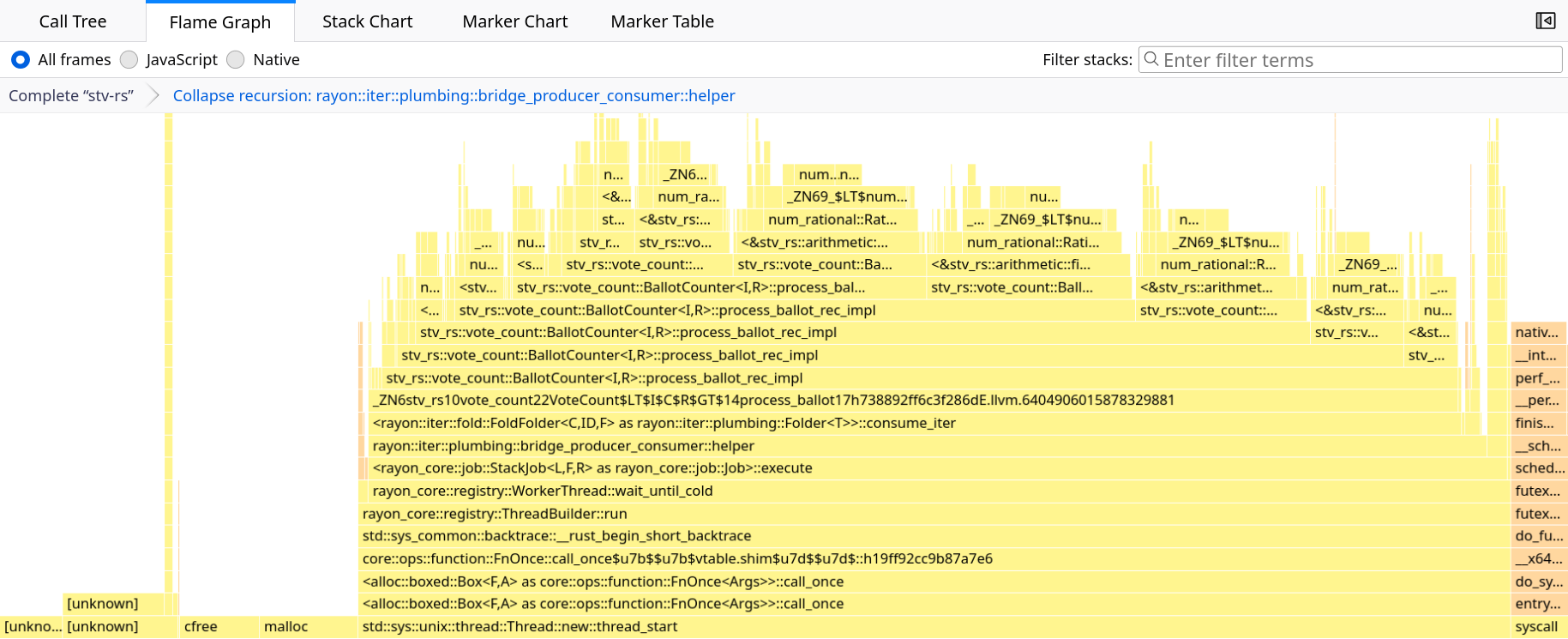 Flame graph with recursion collapsed in the Firefox Profiler.
Flame graph with recursion collapsed in the Firefox Profiler.
Lastly, back to the call tree view, there is an option to invert the call stack. Rather than showing the thread’s main function at the root, it will show a root for each leaf function where the program is actually spending time. It’s still a “forest” structure: you can expand a tree for each function to learn about its callers.
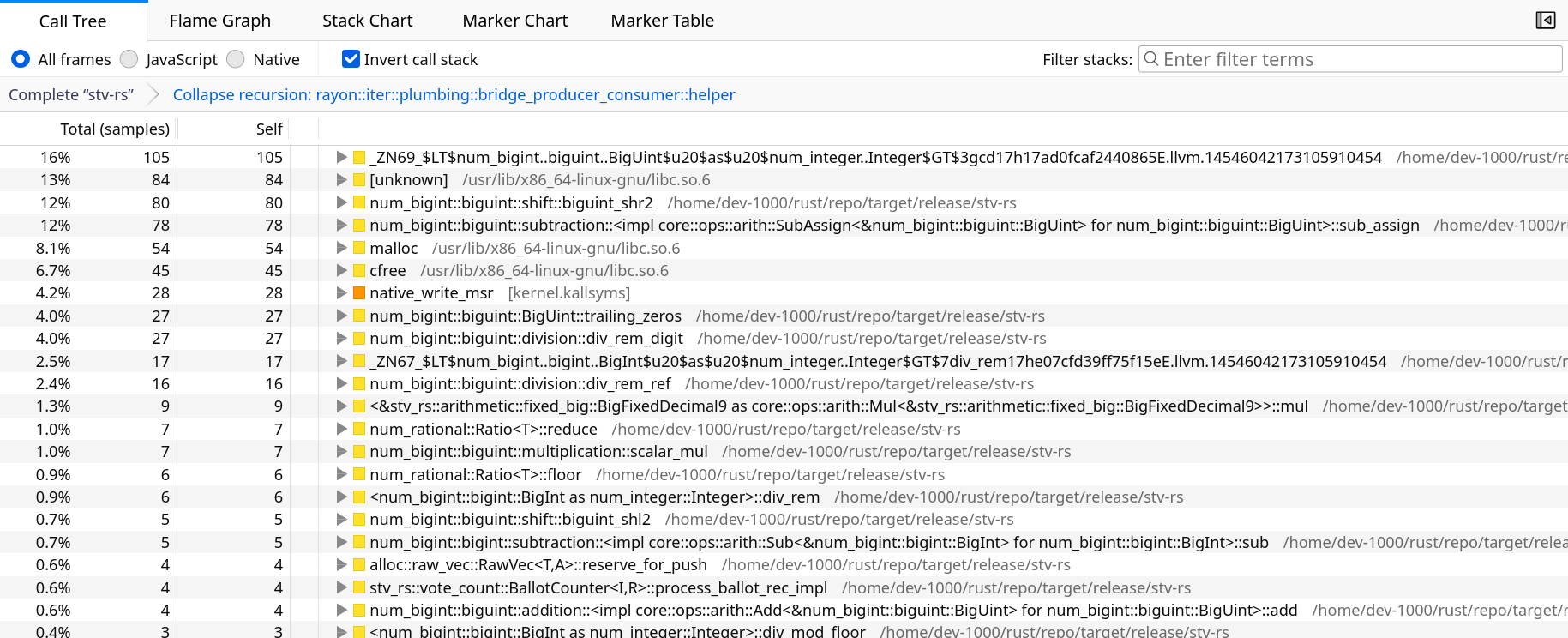 Inverted call stack in the Firefox Profiler.
Inverted call stack in the Firefox Profiler.
In my example, we learn that most of the time is spent performing arithmetic with BigUint, which makes sense as it’s what my parallel loop does.
It also seems that Rayon doesn’t incur direct overhead, but as we will see later overhead can be more subtle and indirect.
Advanced perf usage
So far, we’ve only used perf to record stack traces at a regular time interval.
This is useful, but only scratching the surface.
Another important tool is the perf stat command, which lets you record statistics about plenty of performance counters.
By default, you’ll get basic statistics about the number of executed instructions, the number of CPU cycles (which isn’t proportional to the instructions due to superscalar processors), the number of executed branch instructions and how many of those were branch misses (which is relevant for performance due to speculative execution), etc.
$ perf stat ./target/release/stv-rs <parameters>
22932.25 msec task-clock # 5.864 CPUs utilized
4166 context-switches # 181.666 /sec
7 cpu-migrations # 0.305 /sec
552 page-faults # 24.071 /sec
76612230632 cycles # 3.341 GHz (50.10%)
139165609317 instructions # 1.82 insn per cycle (60.19%)
26963459753 branches # 1.176 G/sec (60.12%)
106756318 branch-misses # 0.40% of all branches (60.08%)
...
These kind of performance counters are recorded regularly as part of the
rustcperformance dashboard, tracking the performance of the Rust compiler over time.
Beyond these default statistics, there is a plethora of performance counters to choose from: the perf list command lists the counters available on your system and the -e flag allows to customize which ones to collect.
In particular, the -d flag (and its verbose mode -d -d) adds counters about cache misses.
$ perf stat -d -d ./target/release/stv-rs <parameters>
...
34611834184 L1-dcache-loads # 1.461 G/sec (26.32%)
22467119 L1-dcache-load-misses # 0.06% of all L1-dcache accesses (26.24%)
4790625 LLC-loads # 202.248 K/sec (20.94%)
50698 LLC-load-misses # 1.06% of all LL-cache accesses (21.10%)
<not supported> L1-icache-loads
69732259 L1-icache-load-misses (21.33%)
...
Some other useful flags:
-r <number>will run your program repeatedly to collect the average value of each counter,- the
:uand:ksuffixes distinguish events generated in userspace and in the kernel (see “event modifiers” in the documentation).
$ perf stat -r 10 -e cycles:u,instructions:u,cycles:k,instructions:k ./target/release/stv-rs <parameters>
Performance counter stats for './target/release/stv-rs ...' (10 runs):
75989870908 cycles:u ( +- 0.51% )
138866699395 instructions:u # 1.83 insn per cycle ( +- 0.00% )
785332709 cycles:k ( +- 0.57% )
356062488 instructions:k # 0.45 insn per cycle ( +- 0.29% )
4.945 +- 0.198 seconds time elapsed ( +- 4.01% )
You can also combine performance events with flame graphs, by sampling a stack trace every time a given event happens (rather than at a regular time interval). This is useful if you want to check which parts of your code trigger cache misses for example.
$ perf record -g -e <event> -c <interval> ./target/release/<binary>
As before, the
-eflag controls which event to sample (e.g.branch-misses). Additionally, the-cflag allows to throttle how often an event should yield a stack trace. For example-c 100will record a stack trace every 100 events. This is useful for frequent events, to avoid interfering too often with the program and to reduce the size of the performance report file.
A word about CPU caches
An important class of events that shows up in perf stat is cache misses.
The physical reality of hardware is that RAM is slow, so in practice CPUs use a combination of very fast registers directly on the computing units, and typically 3 levels of cache.
However, while computers have had gigabytes of RAM for a long time, CPU caches are still ridiculously small.
For example, the lscpu command reveals that my 6-year-old 4-core Intel-based laptop has: one L1 data cache of 32 KB per core, one L1 instruction cache of 32 KB per core, one L2 cache of 256 KB per core and a single L3 cache of 8 MB overall.
All of that with 8 GB of RAM!
$ lscpu -C
NAME ONE-SIZE ALL-SIZE WAYS TYPE LEVEL SETS PHY-LINE COHERENCY-SIZE
L1d 32K 128K 8 Data 1 64 1 64
L1i 32K 128K 8 Instruction 1 64 1 64
L2 256K 1M 4 Unified 2 1024 1 64
L3 8M 8M 16 Unified 3 8192 1 64
Due to these constraints, optimizing CPU cache usage is essential to achieving higher performance, as demonstrated by the talk Cpu Caches and Why You Care by Scott Meyers. Here are a couple of examples.
- A common strategy to improve performance is therefore to compact data structures to fit more of them in cache. We’ll see a practical example in the next post.
- The cache hierarchy can give surprising effects when parallelism is at play.
For example, there are only 4 copies of the L1/L2 caches: one per core.
This means that even if the CPU supports running 2 threads per core in parallel – as
std::thread::available_parallelism()returns on my machine – these threads compete on the caches! So even if the theoretically available parallelism is 8 threads, you can experience a performance wall at 4 threads as was the case in my previous benchmarks.
A hand-rolled replacement of Rayon?
After all of this profiling, it was clear that nothing was clear. So I set out to dig deeper into how Rayon works and see if I could find improvements.
In this section, I’ll briefly introduce my understanding of how Rayon works, and then describe how I built a faster replacement for my use case, by applying simple ideas. It may seem crazy to think that one could improve over Rayon, given how much of a gold standard it is in the Rust ecosystem, with more than 7 million downloads per month (and steadily growing). The Rust compiler itself uses Rayon to parallelize tasks.
One aspect is that Rayon is a generalist library that focuses on a straightforward API, so there was still hope to find improvements by specializing for a given use case and dropping the API simplicity.
How does Rayon work?
In order to improve something, it is useful to know of how it works. Rayon was started in 2015 by Niko Matsakis who described the overall design in the blog post Rayon: data parallelism in Rust, and a series of follow-ups.
- In particular, Rayon is based on the idea of splittable items of work, and on a fundamental join primitive. This allows to distribute and re-balance work across threads via work stealing. This paradigm is generally expressive, as illustrated by the quicksort example.
- Above that, Rayon provides a drop-in replacement of the standard library’s
IteratorAPI and its various combinators likemap(),filter()orfold().
In more detail, the first building block of Rayon is the rayon_core crate.
It manages a pool of worker threads that are constantly polling for new tasks to run, and gradually go to sleep if they find no work to do.
More precisely, it uses the crossbeam::deque data structure to distribute jobs among threads.
This deque works as follows:
- Each thread owns a local queue where it can push and pop items of work.
- If a thread’s queue is empty, it can steal a job from another thread.
- Additionally, a global injector queue allows external components to push items of work into the thread pool.
 Work stealing among threads with
Work stealing among threads with crossbeam::deque.
Above the thread pool, Rayon’s implementation of the ParallelIterator API is rather complex, with the main concepts defined in rayon::iter::plumbing and described in more detail in the plumbing README.
In particular, a pipeline of iterator combinators is organized as a series of producers and consumers, with folders, reducers, callbacks, and a bridge() function to connect them.
To take a concrete example, let’s see what happens when my program calls par_iter() on a slice.
ballots
.par_iter()
.map(|ballot| {
let mut vote_accumulator = VoteAccumulator::new(num_candidates);
process_ballot(&mut vote_accumulator, ballot);
vote_accumulator
})
.reduce(
|| VoteAccumulator::new(num_candidates),
|a, b| a.reduce(b),
)
First of all, the chain of iterator combinators creates a chain of nested data structures. This is similar to what happens with standard iterators in Rust.

Then, a series of callbacks is triggered, eventually invoking the bridge_producer_consumer() function.
This one connects a producer that yields items from the slice with a consumer that applies the reduction function to obtain a result.

This is where parallelism comes into play. The bridge is given as input a subset of the production pipeline (in our case a sub-slice) and can decide to either split it into two halves, or process all of it serially. In case of a split, two jobs are created:
- The first job is processed directly on the current thread, which can in turn either split it again or process it serially.
- The second job is pushed on the local queue, where it may be stolen by another thread if the current thread is too slow to process the first job.

The policy to control when to split is based on the producer’s min_len() function (which can be adjusted manually by calling with_min_len()), as well as the number of threads in the pool and whether a job has been stolen (see the Splitter implementation).
With that, processing our slice in parallel with Rayon is equivalent to creating a binary tree of sub-slices, where each leaf is processed serially. This tree is not necessarily balanced, as the decision to split each node is done locally.

Each job can be executed by any thread.
Although Rayon’s approach is generalist and allows arbitrarily complex patterns, some design choices incur overhead. For example:
- Until they go to sleep, worker threads are constantly polling for new jobs even if there is currently no active
.par_iter()loop. This explains why I noticed so manyfutexandsched_yieldsyscalls. - The overall architecture with a binary tree of splittable jobs creates trade-offs.
- If jobs are too small, there will be a lot of traffic and synchronization in the
crossbeam::dequeto push and pop them. This is why Rayon stops splitting jobs at some point. - However, if jobs are too big then work stealing becomes less effective, because once a job is scheduled to run serially it cannot be split after the fact. This means that if the load is not balanced – because we’re unlucky or due to adversarial inputs – there is a risk that all the heavy items end up in a single serial job without any effective parallelism.
- If jobs are too small, there will be a lot of traffic and synchronization in the
Hand-rolling a thread pool
In summary, while Rayon’s building blocks make sense, it became clear that finding performance improvements in this complex framework would be hard for me. So I went to the drawing board, designing a “mini-Rayon” from scratch and tailored for my use case, to see how the performance would be.
As a reminder, the overall flow of the election counting algorithm I’m trying to parallelize is the following. The second step – iterating over a slice containing all the ballots – is the one to parallelize.
// Step 1: initialize weights.
let mut weights = initialize_weights();
loop {
// Step 2: accumulate votes over all ballots.
let count = ballots
.iter()
.map(|ballot| count_ballot(&ballot, &weights))
.reduce(/* ... */);
// Step 3: update weights and exit if we elected enough candidates.
if update_weights(&mut weights, count) {
break;
}
}
Here was my first, simple strategy to parallelize step 2 manually.
- Create a pool of worker threads that will each process a sub-slice of the input ballots.
- Establish a communication channel (via Rust’s
Mutex+Condvar) for the main thread to tell the worker threads when they can start processing the slice at the beginning of step 2. - Likewise, establish a communication channel for the worker threads to send back the results once they have completed step 2.

This requires sharing the following memory between threads.
- Each worker thread gets a read-only view to the ballots
&[Ballot]. Thestd::thread::scope()function allows creating threads with a scoped lifetime, so that they can capture non-static objects by reference. - Share the additional
weights(that change for each iteration of the main loop) between the main thread and the workers via anArc<RwLock<_>>. A mutex would work too, but aRwLockis much more efficient as it allows all the worker threads to read the weights simultaneously. - Share the results from each worker thread to the main thread via an
Arc<Mutex<_>>.
Lastly, we need to attribute to each worker thread a subset of the ballots to process.
A simple strategy is to partition the ballot slice in advance so that we don’t need additional communication.
For example, with 100 ballots and 4 threads, we can attribute the 0..25 range to thread 1, the 25..50 range to thread 2, etc.
We will revisit this strategy below.
With this basic design, my code worked but was up to 50% slower than Rayon, especially when using more threads.
CPU pinning
One problem with this naive implementation was that the operating system’s scheduler can freely move the execution of each thread from one CPU core to another, by doing a CPU migration – as shown in the perf stat output.
This is in principle good to balance the load across cores, but it incurs unnecessary overhead when we’re utilizing all cores anyway.
Migrating a thread has a cost in itself (running some logic in the kernel to move the thread), but is also detrimental in the medium term because it invalidates per-core caches. Indeed, if a thread had all its working data in the L1 or L2 caches (which are core-specific), moving it to another core will make the thread lose this cached data.3

In my case, the relevant data is the input slice of ballots, which is accessed repeatedly due to the main loop. With the simple partitioning strategy, each worker thread only uses and caches a fixed subset of the input, with no overlap between the inputs that different worker threads manipulate. Therefore, a CPU migration of a worker thread to another core will lead to cache misses (unless the thread migrated back and forth and the data was still in cache).
Fortunately, Linux allows to prevent CPU migrations by programmatically pinning each thread to a set of cores via the sched_setaffinity() function, restricting where the thread can be executed.
By pinning each thread to a single distinct CPU core when we create the thread pool, we prevent migrations.
use nix::sched::{sched_setaffinity, CpuSet};
use nix::unistd::Pid;
for id in 0..num_threads {
let handle = thread_scope.spawn(move || {
let mut cpu_set = CpuSet::new();
if let Err(e) = cpu_set.set(id) {
warn!("Failed to set CPU affinity for thread #{id}: {e}");
} else if let Err(e) = sched_setaffinity(Pid::from_raw(0), &cpu_set) {
warn!("Failed to set CPU affinity for thread #{id}: {e}");
}
// Insert worker thread loop here.
});
}
This indeed gave a good performance boost to the hand-rolled solution, allowing to get slightly ahead of Rayon, which doesn’t do CPU pinning. Depending on the scenario, my code was now up to 10% faster than Rayon with 4 threads, and up to 20% faster with 8 threads.
Work stealing
A big drawback of the fixed partitioning strategy – based on the number of items – is that the load may not be balanced between threads. Indeed, some items may be heavier to process than others, depending on their inherent complexity (e.g. how many candidates are ranked in a ballot) and on the weights of each round. If one worker thread gets all the heavy items, the other threads will finish before and stay idle, which isn’t optimal in terms of parallelism.

To test that, I’ve created biased inputs where the items are sorted by a complexity heuristic, so that each thread would (on average) have less work to do than the next one.
To counter this problem, I implemented work stealing. The principle is the same as with Rayon: whenever a thread finishes processing its own work, it will try to steal work from other threads. However, my implementation is simpler (because specialized for slices), bypassing the overhead and complexity of the concurrent queue and tree of jobs.

Given that the items are contiguous when processing a slice, we can model the set of items “owned” by a thread as a range of integers (as we did without work stealing). The idea is that each thread will pop items from the front of its range until it’s empty, and then look for another thread’s range to steal. In that case, the “thief” will split the stolen range in two, taking one half for itself, and subsequently popping items from the front of it.

An important performance aspect is that stealing is an expensive operation, so we want to steal items in bulk rather than one at a time, to minimize the number of thefts. Indeed, finding a range to steal and telling the “stolen” thread about it requires synchronization (via a mutex or atomics).
Additionally, when the thief thread switches to another range of items, it creates a “jump” that disrupts the natural flow of processing items sequentially, and doesn’t play well with the CPU prefetcher in terms of caching. In other words, the first few items after each jump will likely not be in cache, because the prefetcher cannot predict the jump.
To reduce these costs, I’ve applied two techniques.
- The thief steals the second half of the range. That way, the stolen thread isn’t disrupted too much as it continues processing items sequentially without any jump.
- Rather than trying to steal from the first available thread (greedily), the thief scans all the threads and steals from the largest available range. Even though it makes each theft more expensive in the short term because it’s more work to read all the ranges and find the largest one, each theft is much more effective as both the thief and the stolen thread stay busy longer afterwards. For my workload, I’ve measured 5 times fewer thefts than with a naive “steal from the next available neighbor” strategy.
By stealing ranges of items, we get a major advantage over Rayon: stealing is adaptive and granular. Rather than deciding ahead of time whether to further split a range or not, splits happen dynamically whenever a thread becomes idle. If there is a big imbalance between items, the granularity can automatically adapt from stealing large ranges down to stealing a single item.
A drawback is that each iteration requires some synchronization to tell the other threads which range of items they can steal. However, in practice this cost should be relatively small in the uncontended case where each thread is popping its own items, only getting higher in the rare case when a thread interferes by trying to steal.
With all of that, I generally saw a performance improvement over Rayon, especially as the number of threads go up. Even in the worst case, my implementation performed as fast as Rayon.
Conclusion
My initial assumption was that the Rayon framework caused a non-trivial synchronization overhead when many threads are involved. After digging deeper and implementing a custom parallelism mechanism for my use case, I indeed managed to shave off system calls and in some cases get a performance boost over Rayon. I notably learned that Rayon’s work stealing doesn’t go down to the granularity of individual items, but creates a binary tree whose leaves can be large sub-slices. If the input is imbalanced, this can lead to one thread making slow progress while all the others are done (and spin around with system calls to find more work that doesn’t come).
But while it’s easy to outperform a Swiss Army knife with a custom tool, the hard part is to generalize to other scenarios.
This is where Rayon really shines: its generic approach applies to a very wide range of use cases, and the API is very simple (“just put a par_iter() on it”).
I’m still exploring turning my custom parallelism into a library, to see what are the design trade-offs and hopefully make it useful for similar workloads.
However, whether to use Rayon or not wasn’t even the most impactful performance-wise. In the next post, I will review many other improvements: algorithms, memory representation and generic optimizations.
Bonus: Does Rayon’s with_max_len() help?
As pointed out by Lucretiel on Reddit, Rayon’s parallel iterator trait offers a with_max_len() adaptor, which I had originally missed.
This setting limits how long leaf serial jobs can be in Rayon’s tree of jobs, and is the counterpart of with_min_len().
For example, using .with_max_len(1) should ensure that all leaf jobs have exactly one item, and therefore can be individually stolen.
Given that work stealing gave a performance boost for my custom parallelism implementation, an hypothesis was that using with_max_len() with a small value should speed things up for Rayon as well.
So I implemented a new flag to use with_max_len and benchmarked it on various inputs with 4 threads (the number of CPU cores on my machine).
Unfortunately, this didn’t help for my scenario: setting with_max_len was slower than not setting it, and the speed decreased with the maximum length.
In other words, the overhead of splitting the input into a deeper tree of jobs was larger than the benefit of more fine-grained work stealing.
In the worst case, my program ran twice slower with a maximum length of one (each item gets its own job) than with my custom parallelism implementation.

with_max_len() parameter.
The setting was only effective for heavily skewed adversarial inputs, but even then Rayon still ran about 4% slower than the custom parallelism.

with_max_len() parameter.
This post was edited to take into account feedback on reddit, with the added analysis of Rayon with_max_len() adaptor.
-
I really recommend watching Why does this Rust program leak memory? by fasterthanlime to learn more about the syscalls behind memory allocation. ↩
-
You can also check the code here and run your own instance. ↩
-
The same applies to the instruction cache, but to a smaller degree when all worker threads are running the same code in parallel (just on different data). ↩
Comments
To react to this blog post please check the Mastodon thread, the Lobste.rs thread and the Reddit thread.
You may also like