Syntax and validation of PDF graphics
Version 0.3 of Caradoc was recently released and it includes a major feature for PDF files: validation of graphical instructions. In PDF, graphical content is represented by a sequence of vector graphics commands such as « move to (x, y) », « set color(red) » or « draw path ». These graphical commands follow a specific syntax, distinct from the low-level syntax of objects in a file. Hence, a new validation module was needed for the graphics syntax.
In this post, I introduce the syntax of PDF graphics and explain what verifications are implemented at this layer.
- Organization of graphics in PDF files
- Syntax of graphical commands
- Validation and practical pitfalls
- Conclusion
Organization of graphics in PDF files
In a previous post, I explained how a PDF file is organized into objects. PDF graphics instructions are stored in some of these objects, called content streams. Content streams are mostly used for pages, but it is also possible to describe other objects such as fonts directly with PDF instructions, instead of embedding a third-party format such as TrueType or OpenType.
The page tree
If you ever opened a PDF file, you noticed that the document is organized into pages, that themselves contain graphical content. In practice, each page is represented by a distinct object. The trailer – logical root of the document – refers to the list of pages, which allows to retrieve each page.
However, contrary to one would expect, this list of pages is not stored as an array of references. Instead, they form a tree called the page tree, of which the leaves are page objects. Leaves are naturally ordered from left to right, as shown below.
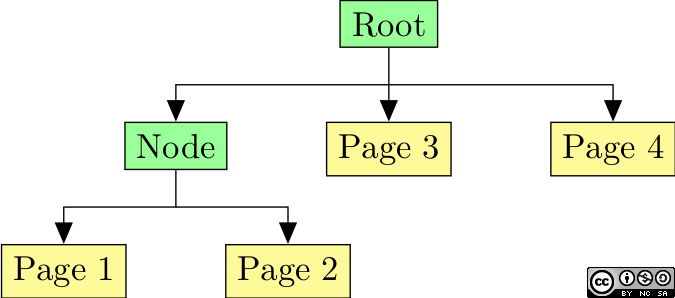 Example of PDF page tree.
Example of PDF page tree.
Then, each page refers to at least one content stream, which contains graphical commands to be drawn on that page. I will explain in the next section how instructions are organized in these content streams.
As we will see, content streams contain only basic instructions, so they often refer to external resources such as images or fonts. These resources are provided by the page. Also, it is important to note that graphical content is separated from interactive content, such as hypertext links. The following figure shows the hierarchy of objects related to a page.
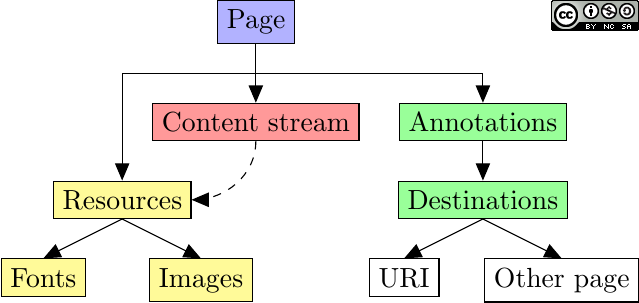 Organization of graphics for pages.
Organization of graphics for pages.
Why a page tree instead of a page array?
The specification gives two reasons to use a tree instead of a simple array of references to organize pages.
First, some attributes can be inherited along the tree. For example, you can define common properties shared by a range of pages, such as the page dimensions or the page rotation.
A page tree node may contain further entries defining inherited attributes for the page objects that are its descendants.
ISO 32000-1:2008, paragraph 7.7.3.2
Second, the specification claims that a tree is efficient in terms of performance.
Using the tree structure, conforming readers using only limited memory, can quickly open a document containing thousands of pages.
ISO 32000-1:2008, paragraph 7.7.3.1
This reason might have been valid in the early 1990s, but it seems that a simpler array structure wouldn’t hurt performance today. Indeed, each reference takes a few bytes, so holding an array of pointers to all pages would not take much space – especially compared to all the graphics processing that a PDF reader has to do. Also, random access should be faster on an array than on a tree.
What’s more, as I mentioned in a previous post, it is not difficult to fool PDF readers with a non-tree structure, e.g. if a node refers to itself as one of its children.
Syntax of graphical commands
As I explained, graphical instructions a stored in content streams. These instructions are quite simple and allow to construct paths, choose colors and related attributes, draw text, etc. I made a one-page cheat-sheet to summarize these instructions, available on GitHub. As you can see, most graphical instructions take a fixed number of arguments of well-defined basic types (number, string, name…).
 Preview of my PDF graphics cheat sheet (link to PDF version).
Preview of my PDF graphics cheat sheet (link to PDF version).
Postfix notation
The syntax of graphical instructions is mostly inherited from PostScript. The memory model of PostScript is based on a stack: for example, there are arithmetic operators (addition, multiplication…) that pop arguments from the stack and put their result back on top of the stack. For this reason, instructions are denoted in postfix notation: the arguments appear first (to be put on the stack), and are followed by the instruction that operates on them (by popping arguments from the stack).
In PDF, there is no more instructions to manipulate the stack. PDF instructions simply take some arguments and return nothing (but have side-effects). In fact, there is no more stack in PDF – although some PDF readers behave as if there were still a stack.
However, the postfix notation is still in use.
For example, to define a line between points (x=5, y=10) and (x=15, y=20), you can use a « move to » instruction m followed by a « line to » instruction l.
5 10 m
15 20 l
The state machine
Graphical instructions can be divided into several categories: setting of graphical parameters (line width, dash pattern, colors, font…), path construction, path painting, text showing, and misc instructions (image drawing, marked content…). Most instructions can only appear in a specific context. For example, a path painting operator must be immediately preceded by path construction operator(s).
In practice, we can represent these contexts as states and each instruction operates a transition between states. For example, a « move to » instruction implies a transition towards the path construction context, in which instructions such as « line to » or « curve to » are allowed. These states and transitions form a state machine summarized below.
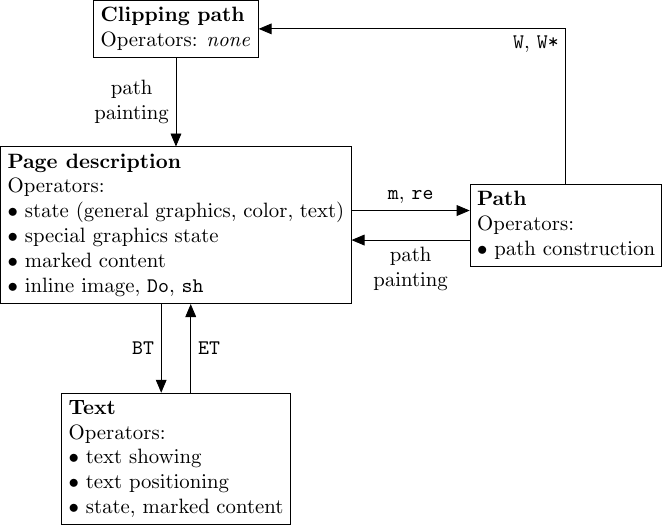 State machine of graphics instructions (simplified).
State machine of graphics instructions (simplified).
Consequently, a validator for PDF graphics must implement this state machine to check that each instruction is allowed in its context. Caradoc performs such verifications.
The graphics state stack
Graphics state instructions modify attributes such as the current font, current colors, the transformation matrix (translations, rotations), the line width, the dash pattern… Together, these attributes form the graphics state. For convenience, there are instructions to save the current graphics state and to restore it later. This is useful to set a temporary value for a parameter and restore the previous value easily.
One can also nest several save instructions, in which case a restore operation corresponds to the latest save operation. We can interpret this as a stack, where the save instruction pushes a graphics state on the stack and the restore instruction pops the top state from the stack.
Naturally, save and restore instructions must be balanced, and Caradoc checks this.
External resources
As I mentioned, some instructions refer to external resources that are not embedded in the content stream. These resources include images and fonts (among others), that are themselves stored in indirect objects. So one could think that you simply need to use an indirect reference to refer to these resources, but this was not the choice made in PDF.
Instead, each content stream is associated to a resource dictionary, that maps names to indirect references to the actual objects. Then, the name of a resource can be used in the content stream.
For example, let’s consider that object 1 0 R contains a font.
A content stream can set this font with a size of 10 by means of the Tf instruction:
/F1 10 Tf
where the associated resource dictionary defines the suitable mapping of the name /F1 to the reference 1 0 R.
<<
/Font <<
/F1 1 0 R
>>
>>
In practice, resource dictionaries are associated to content streams at a higher level. For example, each page object contains a reference to a resource dictionary.
Due to resources, content streams are not self-contained, which means that one could reuse the same content stream (for example in several pages) with distinct resources. In that case, the displayed content would be different for each instance.
This makes the validation of content streams more difficult, because one needs to extract all resources used by the content stream, and compare them to the available resources in all contexts where this content stream appears. For the moment, Caradoc extracts resources used by each content stream, and implementation is in progress to collect information about available resources.
In the future, along with detection of undefined resources, there will be a potential for optimization by detecting resources that are defined but never used.
Validation and practical pitfalls
As we have seen, although graphical instructions follow a rather simple syntax, they can have complex dependencies. In this section, I further describe practical problems related to implementation and to the subtleties found in real-world PDFs.
Parsing postfix syntax
As I explained, PDF graphical commands are serialized using a postfix notation, inherited from PostScript.
The postfix notation allows to easily interpret stack-based languages such as PostScript, by simply scanning tokens linearly.
However, in the case of PDF, there is no command to manipulate the stack: no arithmetic operators, no reading/writing/duplicating of elements on the stack.
In other words, a content stream simply contains a sequence of arguments1... command1 arguments2... command2 and so on.
Although this seems simple to parse, there are some practical pitfalls. To parse the content, Caradoc uses a parser generator for OCaml called Menhir. With a parser generator, you simply need to describe the language by providing grammar rules and the tool automatically converts it into code, while verifying the soundness of the grammar. This removes a lot of programming errors compared to writing parsing code directly, and the generated code has a guaranteed run-time complexity.
However, parser generators often limit the expressiveness of the grammar, to be able to validate the grammar and generate fast code. In particular, it is simpler to write a grammar for a prefix syntax than a postfix syntax – because with a prefix syntax each command gives the context for the arguments that follow.
Hence, I implemented validation of graphical commands by parsing them backwards. This involves some workarounds to reverse the order of tokens, but the grammar rules are much simpler to write, which reduces the risk of programming errors. This also means that errors are reported in a non-intuitive order, i.e. the last syntax error is reported instead of the first one.
Commands split into several streams
Once I implemented the parser for content streams, I tested it on real-world PDF files. However, there is a practical problem that I didn’t expect.
As I said before, each page can refer to one or several content streams to describe its graphical content. I expected that if a page used several content streams, these streams would be self-contained and in particular would not split between a command and its arguments, and that the state machine would come back to the initial state at the end of the stream.
It turned out that these assumptions do not hold, and in practice content streams are split arbitrarily. This means that one cannot simply look for objects of content stream type (as given by the type-checker) and validate them independently. To overcome this limitation, I chose to move this problem to the normalizer, by adding an option to merge all the content streams referenced by a page. With this new option, I did not make the validator more complex (and more error-prone), and most real-world PDFs could be properly parsed after normalization.
Inline images
Although most images are stored in resources, it is possible to embed inline images directly inside content streams, as long as their size does not exceed 4 KB. These images are similar to regular image objects, which means that they are much more complex than other graphical commands, and also have more complex dependencies. For now, Caradoc simply checks that inline images respect the syntax of graphical instructions and does not perform further validation, but it is definitely something to look at. One could also prefer to blacklist inline images, which can be done by minor modifications of the grammar.
Conclusion
Graphical commands, stored in content streams, are the core of PDF: they describe what to display on your screen or to print on paper. They are quite simple and fit in a one-page cheat-sheet, but the devil is in the detail and complex dependencies make them not so easy to validate.
I leave the following questions unanswered for the moment, but I might address them in future posts.
- How do PDF readers interpret invalid sequences of commands?
- How to detect useless commands to optimize content streams?
Comments
To react to this blog post please check the Twitter thread.
You may also like