Pitfalls of PDF parsing and guidelines for file formats
As explained in my previous post, the Portable Document Format was created in the early 1990s, when the main issue for graphic applications such as PDF readers was performance. The world was not as interconnected as today, and security was not the primary concern for the design of new file formats and parsers.
Today, PDF is one of the common delivery channels for malware, because it is social-engineering friendly (who would suspect a PDF file?) and the attack surface is large due to the complexity of the format. Hence, 130 vulnerabilities in Acrobat Reader were listed as CVEs in 2015, and last week’s update fixed 71 more.
Although PDF syntax is not directly involved in most of these disclosed vulnerabilities (which often leverage the JavaScript or Flash interpreters), ambiguities are often used by malware creators to obfuscate content and to evade malware detectors. In this post, I present some of the flaws in the PDF syntax, and try to derive guidelines for more robust file formats.
- Overview of problematic structures
- Summary of bad design patterns
- Are there parser-friendly patterns?
- Towards a redesign of PDF?
Overview of problematic structures
In this section, I want to highlight some examples of problematic structures in PDF syntax. This is not intended to be an exhaustive list, but to show what could possibly go wrong with real PDF readers. If you are not familiar with PDF syntax, you might want to read my previous post first.
Repeated key in a dictionary
According to the specification, a dictionary cannot contain twice the same key. This makes sense because a dictionary is an associative map, so each key can only be mapped to one value.
However, if you write twice the same key in a dictionary, none of the common PDF readers complain.
Instead, they silently choose one of the two values.
Most of them pick the last value, but there is no reason why a new reader wouldn’t adopt another behavior.
So if you write the following in a PDF file, most readers will associate the value (bar) to the key /Key.
<<
/Key (foo)
/Key (bar)
>>
Text and escape sequences
As I explained in my introduction to PDF, the format is before all text-based. This means that some characters such as whitespace or special characters act as delimiters. So if you want to use one of them in a string or a name, you need to use an escape sequence.
For example, in names the escape sequences are of the form #xy where xy is the 2-digit hexadecimal code corresponding to the escaped character (e.g. if you want to include a space you need to use the escape sequence #20).
However, what happens if xy are not two hexadecimal digits?
If you ask a security guy, they would probably say that the file is invalid and hence shouldn’t be processed, but a software engineer would probably try to ignore this error and parse the file anyway.
In that case, the specification does not answer the question, so let’s test the behavior of common PDF readers!
It appears that none of the readers reject the file, but they have distinct behaviors to cope with this error.
To be more specific, if x is an hexadecimal digit and y is not, some readers (let’s call them A) see 3 characters (#, x and y), whereas others (let’s call them B) just replace the y by zero and see 1 character (whose code is x0).
Some readers output a warning in stderr, but who reads that when they open a PDF file?
This interesting behavior, combined with the one about repeated keys in dictionaries, allows to create polymorphic files, that are interpreted totally differently by different readers.
If you want reader A to see the value (foo) and reader B to see the value (bar) for some key /Key, just write the following.
<<
/Key (bar)
/Dummy#7/Dummy /Dummy /Dummy#7/Key (foo)
>>
So what’s happening here? Reader A will interpret the dictionary as:
<<
/Key (bar)
/Dummy#7 /Dummy
/Dummy /Dummy#7
/Key (foo)
>>
and value (foo) overrides the previous value.
Reader B will interpret the dictionary as:
<<
/Key (bar)
/Dummy#70Dummy /Dummy
/Dummy#70Key (foo)
>>
and only value (bar) is associated with /Key.
By the way, no reader complains about dummy keys in a dictionary.
This trick was used in this polymorphic file.
Generation numbers: who knows what they are for?
One of the greatest mysteries of PDF is generation numbers. As I explained in the previous post, indirect objects are labeled with a pair of numbers: an object number and a generation number. One can imagine that a generation number is used to update an object in a later version of a file, but in practice it’s totally possible to use a fresh object number to update your object. There is no intrinsic meaning of updating an object: you can pretend to replace an old object by a new one that as nothing to do with the first one. What matters is that references are consistent.
These blurred semantics of generation numbers lead to discrepancies among PDF readers.
Let’s assume that you have the reference x 1 R but there is no object x 1 obj ... endobj in your file.
The specification states that a reference to an undefined object must be interpreted as the null object.
However, if there is an object x 0 obj ... endobj in your file, some readers interpret the flawed reference x 1 R as a reference to this object (because the object numbers match)!
It seems that generation numbers add more complexity to indirect objects and references, but the only benefit that they bring is more ambiguity in the format.
Graph structure: lists and trees
At a structural level, indirect objects form a graph whose edges are indirect references. If you display this graph for a real-world PDF, you obtain something like this.
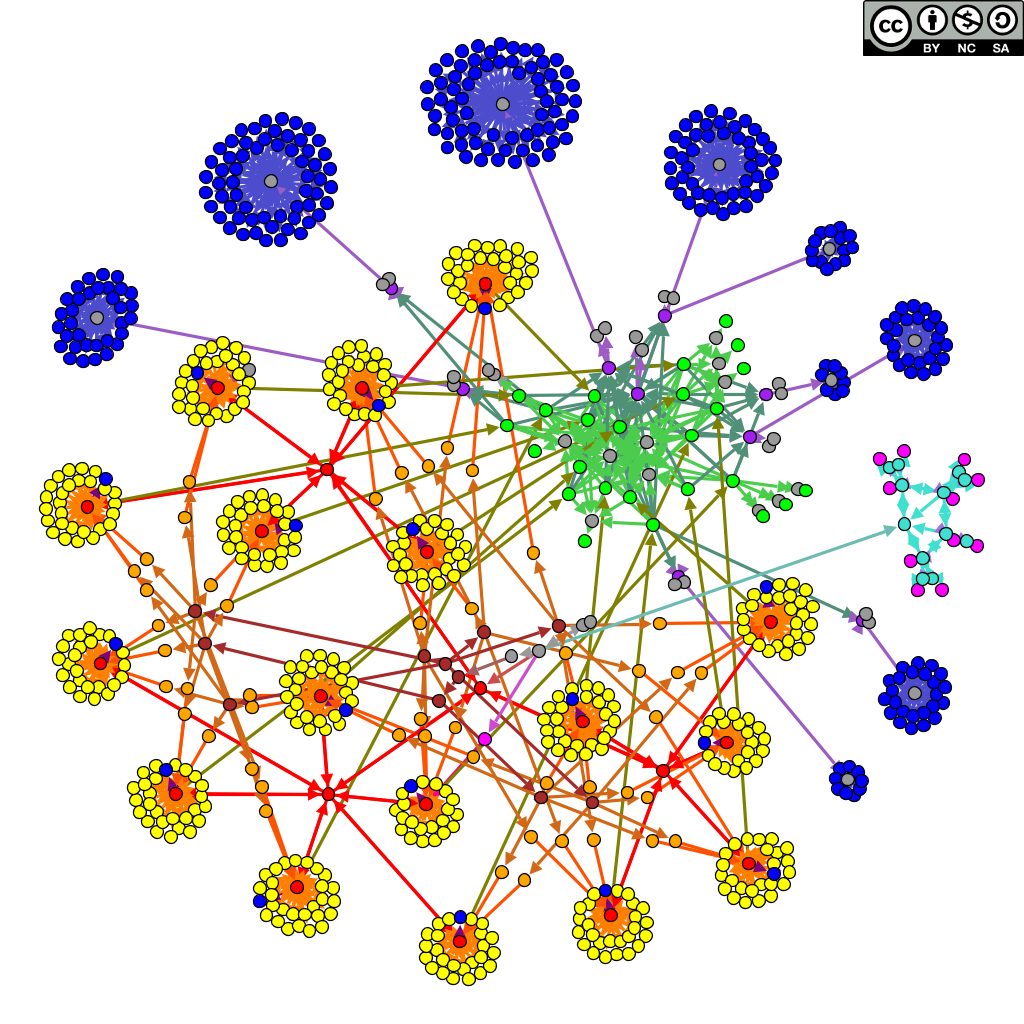 Graph structure of a PDF file.
Graph structure of a PDF file.
We can see that this graph is well structured, and in practice many objects are organized into lists or trees. For example, the pages are organized as a tree: the document root points to the root of the page tree, and each leave represents a page. In the above example, the page tree is shown in red (each page is the center of a cluster of yellow nodes). This structure seems to provide some kind of fast random access (at least it was a design goal for the page tree).
However, what happens if we craft a PDF file with a cyclic structure instead of a tree (e.g. each node has a child that points to itself)? In practice most PDF readers were fooled by such structures and hanged forever or crashed due to infinite recursion. And because tree and list structures are ubiquitous in PDF, none of the surveyed PDF readers implemented proper checks for all of these structures.
The problem of cyclic structures in PDF was also addressed at another layer by Andreas Bogk and Marco Schöpl in 2014 at the first LangSec Workshop. In their example, they created a recursive structure with incremental updates. Indeed, as I explained in my previous post, xref tables and trailers form a linked list where each node corresponds to an incremental update.
Summary of bad design patterns
We have seen several examples of syntactic structures that are problematic from a parsing point of view. In this section, I try to classify these flawed design patterns and to derive guidelines. These remarks could for the most part be extended to other file formats or network protocols.
Redundancy
First, PDF is inherently redundant.
For example, indirect objects are delimited by the keywords obj and endobj, which already allow to retrieve all the objects.
Yet, the xref table(s) also indicate the offset of each object in the file.
This redundancy is problematic from a parsing point of view because there is ambiguity if the position of an object does not match the offset in the xref table. This ambiguity can come from a manually crafted file (e.g. an attacker who wants to obfuscate its malware) or from a bug in a PDF-producing software. Worse, the specification encourages PDF parsers to accept such ill-formed files, although a good practice would be to reject these files.
When a conforming reader reads a PDF file with a damaged or missing cross-reference table, it may attempt to rebuild the table by scanning all the objects in the file.
ISO 32000-1:2008, annex C.2
Redundancy is not parsing-friendly because:
- either a parser relies on only one piece of information (making redundancy is useless), and other parsers may rely on other (and contradicting) pieces of information, which breaks portability;
- or a parser checks consistency of redundant information to reject invalid files, which introduces a performance cost.
Comments and free space
PDF allows to embed comments practically anywhere in the file, but they introduce more trouble than usefulness. Indeed, (almost) nobody reads manually real-world files, and no software writes comments in files. However, comments allow to hide content and facilitate the creation of polyglot files, by putting the content of another file format inside PDF comments and/or vice-versa.
We can also imagine to put unrelated content in the free space between successive objects (without even needing a comment), or in unused objects (i.e. indirect objects that are never referenced by other objects).
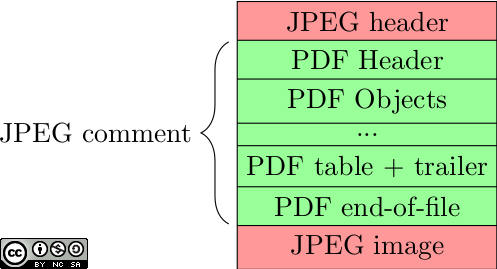 Layout example for a JPEG+PDF polyglot.
Layout example for a JPEG+PDF polyglot.
Comments are in most cases useless and help crafting polyglot files.
Textual format
As a textual format, PDF also introduces unnecessary complexity for parsers. This is in particular true because of inconsistencies in the format or w.r.t. expected behavior.
For example, escape sequences are needed for both strings and names because non-regular characters act as delimiters.
However, to escape a character of code x, the escape sequence for strings is \abc where abc is x in octal, whereas the escape sequence for names is #de where de is x in hexadecimal.
If the format was binary, such character sequences could be encoded with the Tag-Length-Value paradigm, thereby eliminating the need for escape sequences.
Another example is the forbidding of exponential notation for real numbers, although this notation is the norm in most programming languages. Hence, uncarefully-written parsers can accept this notation while conforming parsers will reject it. Here again, binary-encoded numbers do not have this problem. Besides, binary-encoded numbers have inherent range semantics (e.g. unsigned integer between and ), whereas there are no bounds for text-represented numbers (in which case several implementations may convert them to different types, causing discrepancies among implementations).
Prefer binary to text unless your format is really intended to be edited by humans. And keep in mind that SQL injection attacks leverage the textual nature of the format!
Layers of band-aid for backward compatibility
Although PDF has been around for 25 years and has known 8 major versions, it is still backward compatible. It may seem a bit surprising given that the computing landscape has evolved dramatically over this time: the major concern of yesterday was performance, the main problem today is security.
Backward compatibility at all costs is problematic because in order to fix mistakes of the past, one needs to add more layers of complexity on top of it. For example, putting the xref table at the end was clearly a problem because we cannot randomly access objects while the file is downloading. A simple fix would be to move the table at the beginning, but instead the hybrid scheme of linearization was invented, which is overly complex and increases redundancy.
Be ready to break backward compatibility to fix the mistakes of the past, or complexity will explode and security issues will follow.
Are there parser-friendly patterns?
After reading all these examples about how flawed PDF is, you may think that there is no such thing as a secure file format and that trying to design better formats is a lost cause. However, I want to finish this post on an optimistic note, by showing some examples of good patterns that can be used to exchange structured data with untrusted parties.
The first thing to have in mind is the KISS principle. Keep it simple and stupid. Indeed, the simpler the syntax, the easier it is to write a correct parser for it. Applied to the example of PDF, this means that the pages should be organized as a flat array. Period. There is no need to have a fancy tree structure, because you’ll need to check this structure anyway if you want to build a robust parser.
To be more specific, a nice building block is the Tag-Length-Value (TLV) pattern. Each field contains a small header that indicate its type (the tag) and the payload length, and then the payload follows. After the payload, you directly have another TLV field. For example, the PNG image format (RFC 2083) is made of TLV fields. In the case of PDF, this pattern could be used to represent strings or names, thus eliminating the need for escape sequences.
Another good news is that today you don’t even need to design a format and to write a low-level parser (unless you have really specific needs, e.g. performance is critical for your application). For example, with the Protocol Buffers released by Google, you only need to write the schema of your format and pass it to the Protocol Buffers compiler. This will check for inconsistencies in your schema and automatically generate code to serialize your data (available for most common programming languages). Of course you still need to create a meaningful schema and to check inputs at a (higher) semantic level, but at least you avoid the common pitfalls of low-level parsing.
Towards a redesign of PDF?
We have seen that the current syntax of PDF raises several issues. Portability was a design goal of PDF (at least if we take the name literally), but because the format is so complex and the specification contains many ambiguities, it is not difficult to write non-portable or polymorphic files.
Besides, the various versions of PDF have added a lot of new features, which increases the attack surface from a security point of view, although most of these features are rarely used. A much simpler format could fit for most use cases (i.e. viewing and printing a document), whereas the most advanced features (interactive forms, 3D figures, sound, JavaScript) could be left to a more complex format.
It might be time to break backward compatibility to obtain a simple, portable and reliable document format, for which secure and robust parsers are obvious to build.
Comments
To react to this blog post please check the Twitter thread.
You may also like