Introduction to PDF syntax
In popular belief, PDF is often seen as an obscure binary format that is almost impossible to modify. This is partly true, in the sense that the format is so complex that it would take years as a full-time job to fully understand it.
However, it is possible to parse, analyze and validate PDFs, and these were the objectives of the Caradoc project. After my work on this project (still in progress), I am starting a series of posts to demystify the Portable Document Format and share some relevant feedback. In this first post, I give an overview of the PDF syntax.
What is PDF?
From a historical perspective, PDF stems from PostScript, a vector graphics format born in the 1980s. The first PDF reader was released in the early 1990s, and PDF was later formalized as an ISO standard (number 32000-1) in 2008. This means that a PDF specification was published, and you can indeed find a copy on Adobe’s website.
After downloading this document (itself delivered as a PDF file!), you can have a nice 756-page reading, or just lazily follow my summary blog posts. The specification is sometimes quite verbose, but the section titles are mostly self-explainatory, so we will start this journey at section 7 (Syntax).
Syntax of objects
Contrary to what people expect, PDF is before all a textual file format, whose syntax is mostly inherited from PostScript. This means that a human could in theory write or read it manually, but I don’t know many people who do it with real files.
In practice, the textual nature of PDF means that bytes are grouped into several character classes:
- white-space, to separate tokens:
0x00(null),0x09(horizontal tab),0x0A(line feed),0x0C(form feed),0x0D(carriage return),0x20(space); - delimiters, to construct tokens:
()<>[]{}/%; - regular characters: all the other bytes.
Basic objects
A PDF document is structured into objects. Think of these objects as JSON (RFC 7159), but with a different syntax. They are composed of the following data types.
- The
nullobject. - Booleans, represented as
trueandfalse. - Integers, such as
123or-456. - Real numbers, such as
1.23or-0.456(exponential notation such as1.23e4is not allowed, one must use leading/trailing zeros instead). - Strings, delimited by parenthesis such as
(foo)or(Hello world\n)(the backslash\is used to escape characters). They can also be in hexadecimal, between angle brackets like<48656C6C6F20776F726C64>(equivalent to(Hello world)). - Names, introduced by a slash
/such as/baror/Hello#20world(the number sign#is used to escape characters). - Arrays, represented as space-separated objects surrounded by square brackets, such as
[123 456 789]or[[123 (foo)] /bar true 45.6]. - Dictionaries, that contain key-value pairs surrounded by double angle brackets, where the keys are names, such as
<< /key (value) /foo 123 >>. Here is a real-world example:
<<
/C [0 1 0]
/Rect [149.373 465.656 159.335 472.481]
/Type /Annot
/A <<
/S /GoTo
/D (24)
>>
/Border [0 0 1]
/Subtype /Link
>>
Additionally, one can insert comments, starting with a percent sign % and finishing with an end-of-line marker (\r, \n or \r\n).
Indirect objects
Basic objects already provide an expressive language, but the format also defines indirect references, that can be viewed as pointers between objects. This is useful for several reasons:
- to share the same data between several objects, for example several pages can make use of the same font to render text;
- to create graph structures such as trees or linked-lists.
If you want to point to some object, you first need to embed it in an indirect object.
An indirect object is identified by an object number and a generation number.
For example, the following indirect object has an object number of 1 and a generation number of 2.
1 2 obj
(I am an indirect object)
endobj
We can then refer to this object by using an indirect reference, represented by 1 2 R.
Streams
Streams are a special case of indirect objects, that contain a dictionary along with a byte sequence. This is for example used to encode images, where the dictionary contains metadata (file dimensions, color space, etc.) and the byte sequence contains the pixel colors. Streams also allow to compress a byte sequence, by indicating compression filters in the dictionary.
The syntax is as follows.
123 456 obj
<<
% stream dictionary
>>
stream
% stream data
endstream
endobj
File layout
Now that we know how to create objects, we can move on to the file layout, that is how to organize these objects in a file. A basic PDF file contains the following elements:
- the header indicates the file format and version (represented as
%PDF-1.xwherexis the minor version, from0to7); - the body contains a sequence of indirect objects;
- the cross-reference table (a.k.a. xref table) indicates the positions of objects in the file, to allow random access;
- the trailer is the logical root of the document (for example the trailer points to the list of pages);
- the end-of-file marker indicates the location of the xref table.
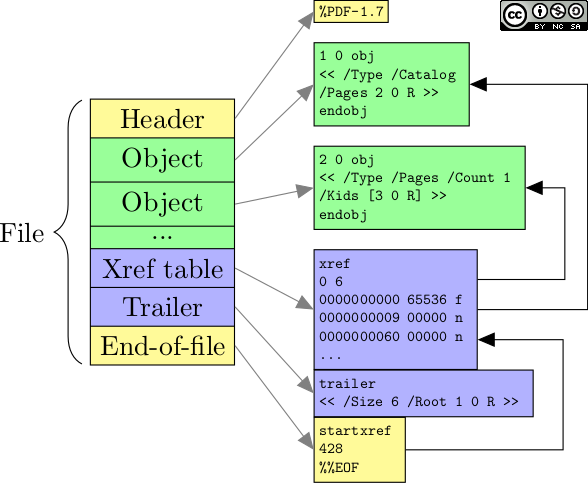 Layout of a simple PDF file.
Layout of a simple PDF file.
With these elements, it is already possible to create a simple file, and a full « Hello world » file looks like this (here on GitHub). In this example, there are 6 indirect objects, which is roughly the minimum for a conforming file.
Show Hide
%PDF-1.5
%
1 0 obj
<<
/Type /Catalog
/Pages 2 0 R
>>
endobj
2 0 obj
<<
/Count 1
/Kids [3 0 R]
/Type /Pages
>>
endobj
3 0 obj
<<
/Resources <<
/Font <<
/F1 5 0 R
>>
>>
/MediaBox [0 0 700 200]
/Parent 2 0 R
/Contents 4 0 R
/Type /Page
>>
endobj
4 0 obj
<< /Length 35 >>
stream
BT /F1 100 Tf (Hello world !) Tj ET
endstream
endobj
5 0 obj
<<
/Name /F1
/BaseFont /Helvetica
/Type /Font
/Subtype /Type1
>>
endobj
6 0 obj
<<>>
endobj
xref
0 7
0000000000 65535 f
0000000015 00000 n
0000000066 00000 n
0000000126 00000 n
0000000265 00000 n
0000000350 00000 n
0000000434 00000 n
trailer
<<
/Size 7
/Root 1 0 R
/Info 6 0 R
>>
startxref
454
%%EOF
Major evolutions of the structure
The first PDF reader was released about 25 years ago. Since then, the format has evolved and the specification has known eight major versions: from 1.0 to 1.7. During all this time, many new features appeared (multimedia support, JavaScript integration, etc.). But the format also evolved at a syntactic level, to cope with more use cases. I will now describe the major syntactic structures that differ from the basic structure.
Incremental updates: who said that PDF was read-only?
Contrary to popular belief, PDF is not meant to be a read-only file format. The specification allows to modify a file by appending new content to it. To implement this, you need to append the following elements to the file:
- new objects that describe updated content;
- a new xref table that indicates the offsets of new objects, and possibly invalidates some old objects;
- a new trailer for the whole file, that contains an additional
/Preventry pointing to the first xref table; - a new end-of-file that points to the new xref table.
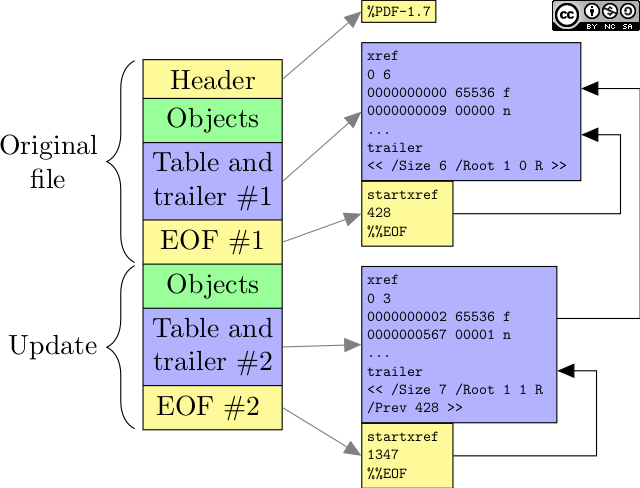 Structure of a file with an incremental update.
Structure of a file with an incremental update.
It is also possible to append several incremental updates, in which case the xref tables and trailers will form a chain. In practice, PDFs with 2 or 3 xref tables are common, and some files found in the wild even have dozens of updates!
Object streams and xref streams: let’s compress!
As I mentioned earlier, PDF is a textual format, which means that its content is verbose and not optimized for small file size. To tackle this problem, version 1.5 introduced the notion of object streams. An object stream is simply a stream that contain other objects in its data segment. Because streams support compression algorithms such as Deflate, the size can be reduced. Consequently, this feature is very popular. In practice, an object stream often contains dozens to hundred of objects.
 Layout of an object stream.
Layout of an object stream.
Note that it is not possible to embed object streams in other object streams. In fact, you cannot put streams inside object streams, but only basic objects.
In the same spirit, xref streams were introduced to compress xref tables: in that case the table is contained in a stream. The trailer will directly indicate the offset of the xref stream, so that we can decode the file. Note that the xref stream being an indirect object, there is an offset for it in the xref table (i.e. in itself), which introduces a form of vicious circle!
Linearization: read me on the web!
As explained earlier, the root of the document is located at the end of the file. This means that when a software reads a PDF file, it must first fetch the xref table at the end, and then it knows where to find the objects. This is problematic in a networking context, because nothing can be rendered before a file is downloaded entirely. The delay can be important, especially for files that contain hundreds of pages or a lot of high-resolution images, or for users with a slow Internet connection.
To counter this problem, another structure was introduced by version 1.2: linearization. The file layout is slightly modified, by introducing the linearization dictionary, an object located at the beginning of the file. This dictionary points to hint tables, that play a role similar to an xref table (but using a totally different syntax). Besides, objects related to the first page and the document root are all placed near the beginning of the file.
This way, a PDF reader in a web browser can recognize the linearization dictionary, fetch the hint tables and render the first page quickly. Downloading continues while the user reads the first page of the document. Once the download is finished, the user can read the full document.
However, linearization is added in parallel to the regular structure. This is to allow any PDF reader to parse the document, even if it does not support linearization. This also means that linearization introduces redundancy and complexity to the file layout. For example, hint tables are redundant with xref tables. Following is a (simplified) sketch of a linearized layout.
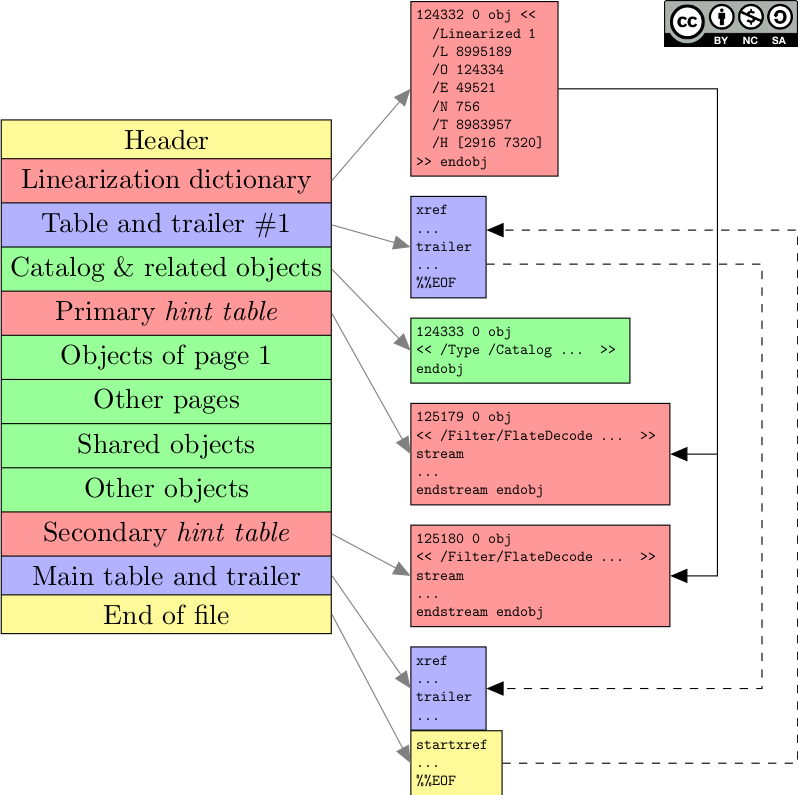 Structure of a linearized PDF.
Structure of a linearized PDF.
You can see that a PDF file can be quite complex, and there is a lot to say about this syntax regarding security and performance, but I will discuss that in more detail in other posts.
Further reading
I hope that this short introduction to PDF syntax was useful! For those who want to learn more about it, stay tuned because other posts are coming soon. In the meantime, you can read the paper about Caradoc that I presented at the 3rd LangSec workshop. It contains complementary details about the syntax, along with some examples of parsing discrepancies between PDF readers.
I also suggest the following resources about PDF:
- PoC||GTFO, a free computer security journal that is distributed as polymorphic PDF files (including JPEG, ZIP, TAR, bootable OS, WavPack audio, Ruby/HTML webserver, etc.),
- a step-by-step introduction to write your own Hello World, Let’s write a PDF file by Ange Albertini,
- examples of hand-crafted files by Ange Albertini and Kurt Pfeifle, in the Corkami and PDF101 projects.
Comments
To react to this blog post please check the Twitter thread.
You may also like