How secure is PDF encryption?
I recently added the parsing of encrypted PDF files to the Caradoc project. This feature is already available in my development branch on GitHub (this implementation is still experimental but should work for most files). I want to give some feedback about it, by describing and analyzing the standard encryption scheme of PDF.
PDF encryption was first introduced in the mid 1990s, which means that cryptography has evolved a lot since that time. In particular, export restrictions on cryptography were limiting the size of cryptographic keys, and many common cryptographic primitives of that time – such as RC4 – are now broken. Newer versions of PDF added more secure primitives – such as AES – but as we will see, the security of PDF encryption still suffers from its legacy.
Throughout this post, I assume that you are familiar with PDF syntax. If this is not the case, I encourage you to read my introduction to PDF syntax.
This post is only based on the PDF reference (ISO 32000-1:2008), but additional encryption algorithms were defined in the ExtensionLevel 3 (an extension of Adobe available here). Besides, I only deal with symmetric-key cryptography, although a public-key cryptographic scheme is also supported by PDF.
- PDF encryption: why and how?
- The encryption dictionary
- Computation of keys and checksums
- Encryption of the content
- Conclusion
PDF encryption: why and how?
Encryption was first introduced in version 1.1 of PDF. Initially, only the RC4 encryption algorithm was supported with keys of only 40 bits (because of export restrictions on cryptography at that time), but the key length was extended up to 128 bits in version 1.4 and AES is supported since version 1.6. As we will see, the MD5 hash function is used in various algorithms, for example to derive cryptographic keys from passwords.
Encryption is defined in section 7.6 of the PDF reference and spans 15 pages, but I endeavor to summarize the main ideas in this post. Encryption serves mainly two purposes in PDF:
- protecting private information;
- enforcing Digital Rights Management (DRM), i.e. to restrict available actions on a document (modifying, printing, etc.).
Contrary to what one would expect, encryption is not done at document level but at object level, and more precisely only strings and streams are encrypted. This means that for example you can retrieve the number of pages of an encrypted document. Some metadata may even be present in clear, thanks to fine-grained control over which objects are encrypted and which are not. This fine-grained encryption is even advertised by Adobe as a practical advantage compared to file-level encryption, although it does not seem to increase security…
DRM is implemented by means of two passwords: the user password is sufficient to decrypt the document, while the owner password allows to verify a checksum depending on the permissions. In other words, it is up to the PDF reader to enforce these permissions. The permissions are encoded in clear, but as we will see, the keys used to decrypt the document are derived from both the user password and the permissions. This means that simply modifying the permission field to unlock all rights will corrupt the encryption keys. However, knowing the user password allows to fully decrypt the file so it is technically possible to manually unlock it (at the expense of implementing a parser that supports the complex PDF syntax).
The encryption dictionary
Encrypted PDFs contains at their root a special dictionary that stores the necessary elements to decrypt the file.
Among others, this /Encrypt dictionary contains the following fields:
/Vand/R, the version and revision, that specify the encryption algorithms to use;∕U, a checksum of the user password;∕O, a checksum of the owner password;∕P, the permission flags;∕ID1, some document-level random value.
It also contains fields to specify the key length and other information, omitted here for simplicity.
When a PDF reader detects that a document is encrypted, it prompts the user for a password and uses the checksum values to choose to further process the file or reject the password. The software may also try a default empty password before prompting the user. This is intended for reading seamlessly DRM-protected files, for which the user password is left empty (whereas the owner password is secret to enforce DRM).
Computation of keys and checksums
Given the user password , the owner password , the permission flags and the document , some ad-hoc algorithms allow to compute encryption keys and to verify the checksum values and . I describe these algorithms to in the following sections. The following figure summarizes the flow of inputs and outputs between them.
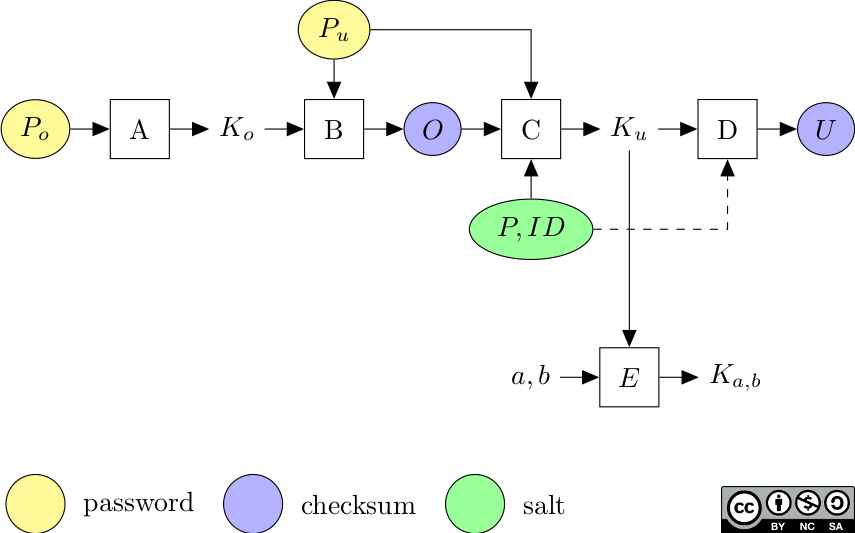 Derivation of encryption keys from passwords.
Derivation of encryption keys from passwords.
These algorithms depend on a constant value , shown here in hexadecimal. How this value was generated is unspecified.
28BF4E5E4E758A4164004E56FFFA01082E2E00B6D0683E802F0CA9FE6453697A
In the following sections, I use the following notations.
Given a string and an integer , means the first bytes of (this is also written [X]_n in pseudo-code).
The concatenation of two strings and is denoted by .
The padding function is defined by ; in other words, is appended to and the result is trimmed to 32 bytes.
(A) Derivation of the owner key from the owner password
The owner key is derived from the owner password . This key is only used to encrypt the user password into the owner checksum . Hence, knowing the owner password allows to retrieve the user password and is sufficient to decrypt the file.
For a key length , was computed as a MD5 hash of the password (with padding and trimming) in the early versions.
H := MD5(pad(P_o))
K_o := [H]_n
The more recent versions introduced more hashing rounds.
H := MD5(pad(P_o))
do 50 times:
H := MD5(H)
K_o := [H]_n
(B) Encryption of the user password into the owner checksum
The owner checksum is an encrypted version of the user password using the owner key .
In the early versions, a simple RC4 encryption was used.
O := RC4(K_o, pad(P_u))
The more recent versions introduced more rounds.
H := pad(P_u)
for i = 0 to 19:
K_i := K_o ^ i
H := RC4(K_i, H)
O := H
At each iteration, the key is slightly modified: the notation K_o ^ i means that each byte of K_o is XOR-ed with the counter i.
The key is different for each round because RC4 being a stream cipher, encrypting a second time with the same key cancels the first encryption.
(C) Derivation of the user key from the user password
The user key is the main encryption key and is sufficient to decrypt the whole file. It is derived from the user password , the owner checksum , the permission flags , the document and the key length as follows.
H := MD5(pad(P_u) || O || P || ID)
do 50 times:
H := MD5([H]_n)
K_u := [H]_n
In the early versions of the algorithm, the loop that rehashes 50 times was not present.
(D) Verification of the user key
The user key allows to compute the user checksum .
If this value matches the ∕U field of the encryption dictionary, PDF readers proceed to decrypt the file.
In the early versions, was simply an RC4 encryption of the padding constant by the user key.
U := RC4(K_u, padding)
The more recent versions also make use of the MD5 hashing algorithm, and use more rounds.
H := MD5(padding || ID)
for i = 0 to 19:
K_i := K_u ^ i
H := RC4(K_i, H)
U := H
First conclusions about the scheme
We have seen that the derivation of keys and checksums from passwords is quite custom and inconsistent. First, derivation of the user key uses a salt (the document ID) whereas derivation of the owner key does not. Second, the hash is trimmed at each round to compute the user key whereas it is only trimmed in the end to compute the owner key . Also, these algorithms rely on cryptographically insecure primitives as of today: the MD5 hash function and the RC4 stream cipher.
Besides, the computation of depends only on the passwords and (it is not salted for example by the document ID). This makes the scheme subject to precomputation attacks to retrieve the passwords (e.g. using Rainbow tables), especially because the owner password defaults to the user password if only one of them is provided.
If there is no owner password, use the user password instead.
ISO 32000-1:2008, paragraph 7.6.3.4, algorithm 3.a
In essence, PDF encryption is weak for the two main use cases:
- privacy protection, in which case and are likely to be identical (unless the creator also wants to enforce DRM or chooses to define a dummy ), and a low-entropy password can efficiently be recovered with a precomputation attack;
- DRM protection, in which case is empty and is secret, but encryption can be removed anyway because is public.
Also, a precomputation attack can be mounted to efficiently retrieve low-entropy owner passwords used for DRM (in which case is empty). Hence, DRM protection as it is implemented in PDF is not only useless against a determined attacker, but it can also expose a low-entropy owner password : this can be detrimental to security if this password is reused for other sensitive services.
Encryption of the content
Now that we have explored the key derivation and verification algorithms, let’s see how the content itself is encrypted.
First, encryption only applies to strings and streams. This means that from a general point of view, an encrypted file has the same structure as a regular file: it is made of indirect objects that themselves contain streams, dictionaries, arrays, numbers, names or strings. However, the sequence of bytes that constitute each string or stream’s content is encrypted individually.
Several encryption primitives are supported in the standard encryption filter: the RC4 stream cipher and the AES block cipher in CBC mode. Besides, each object is encrypted with a distinct key.
(E) Construction of an object key
Let’s consider an indirect object with an object number and a generation number . All the strings and streams contained in this object are encrypted individually with the object key . This key is computed as follows from the user key , where is the key length.
H := K_u || [a]_3 || [b]_2
with AES:
H := H || "sAlT"
H := MD5(H)
K_ab := [H]_n
Defining distinct keys for distinct objects is natural if one uses a stream cipher (such as RC4), because stream ciphers are insecure in case of key reuse. However, this is not properly implemented by PDF because the same key is reused for all the strings in a given object.
Encryption of a string or stream
Let be a plaintext string or stream to be encrypted with . The associated ciphertext is computed as follows.
- For the RC4 algorithm:
C := RC4(K_ab, P). - For the AES-CBC algorithm, the plaintext is first padded with the PKCS#5 scheme (defined in RFC 1423), and a 16-byte initialization vector is prepended to it before encryption:
C := AESCBC(K_ab, R || pad_PKCS#5(P)).
Analysis
We first note that even though each object has its own key, all the strings that belong to the same object are encrypted with the same key. In the case of RC4, this means that they are encrypted with the same keystream, and guessing part of a plaintext allows to recover part of the other strings/streams in the same object. Security of stream ciphers is greatly reduced when a key is reused.
Besides, the context of each encrypted item allows an attacker to guess part of the plaintext (for example a string in a date field is expected to be encoded in a specific format).
More importantly, none of these encryption algorithms provide authentication and integrity of the data. This is in particular problematic for stream ciphers (such as RC4), which are easily malleable.
Conclusion
PDF symmetric-key encryption as defined in the latest ISO specification (32000-1:2008) suffers several flaws.
- Encryption is too much fine-grained: it is only performed locally and is limited to strings and streams, which means that an attacker has full knowledge of numeric values (such as the number of pages) and knows the context of each encrypted element (such as its expected type). This was intended for « practicality », but it also gives more power to attackers. File-level encryption should be used instead to protect sensitive documents.
- Algorithms used to derive encryption keys from passwords rely on primitives that are not cryptographically secure by today’s standards (MD5 and RC4). These key-derivation functions are really ad-hoc and use too few rounds, which make them weaker than algorithms such as PBKDF2, bcrypt or scrypt.
- In particular, the
/Ovalue is a non-salted function of the user and owner passwords, which means that precomputation attacks are possible to recover passwords. - Although the data is encrypted, integrity is not protected. Modern modes of operation that provide authenticated encryption should be used instead.
Regarding DRM, there is no guaranty against someone who knows the user password (which is necessary to read the file anyway). The fine-grained level of encryption with object-dependent keys only slightly hinders someone determined to unlock the permissions (but this is mostly security through obscurity). The fact that the specification describes each key-derivation algorithm with verbose text when a few lines of code would be much clearer might also help repelling the script kiddies. But another consequence is the thrive of dubious software such as « secure PDF unlocking » online services.
-
Technically the
/IDfield is not in the encryption dictionary but directly in the catalog, though it does not seem to serve other purpose than encryption. Also, it contains two elements, but only the first one is used for encryption. ↩
Comments
To react to this blog post please check the Twitter thread.
You may also like